Epoch Capabilities Index (ECI)
A methodology for tracking AI capability progression over time, introduced in Anthropic’s RSP evaluations for Claude Mythos Preview. Based on Epoch AI’s implementation of Ho et al.’s “A Rosetta Stone for AI Benchmarks.”
How It Works
Item Response Theory (IRT)
ECI uses Item Response Theory to aggregate performance across many benchmarks into a single capability score per model. This allows:
- Stitching together different benchmarks (internal + external) onto a common difficulty scale
- Estimating a model’s score from any subset of benchmarks
- Tolerating sparse data (not every model needs to be tested on every benchmark)
- Placing models and benchmarks on the same scale (so you can see which benchmarks are “below” a model’s level)
Anthropic’s internal version includes ~300 models and hundreds of benchmarks (mostly internal), joined with Epoch’s public dataset. The stitch between internal and external scores is sparse, so the internal ECI scores are not directly comparable to public ones.
Slope Ratio (Acceleration Detection)
To detect capability acceleration, a two-piece linear fit is applied to the ECI-over-time trend:
- The trend is split at a breakpoint (a specific prior model)
- The late-segment slope is divided by the early-segment slope
- A ratio > 1 suggests the capability trajectory has bent upward
Results for Claude Mythos Preview
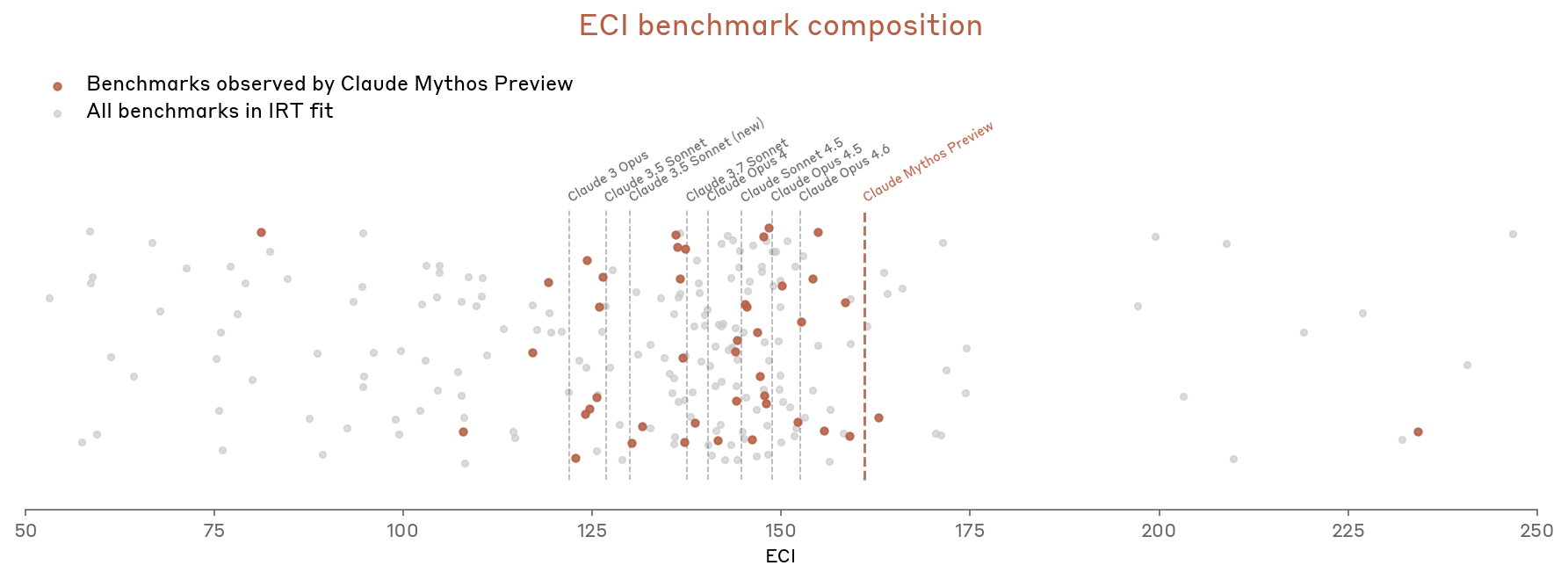
Figure 2.3.6.A — ECI benchmark composition, p. 41. Most benchmarks land below Claude Mythos Preview’s ECI level, widening uncertainty in its score.
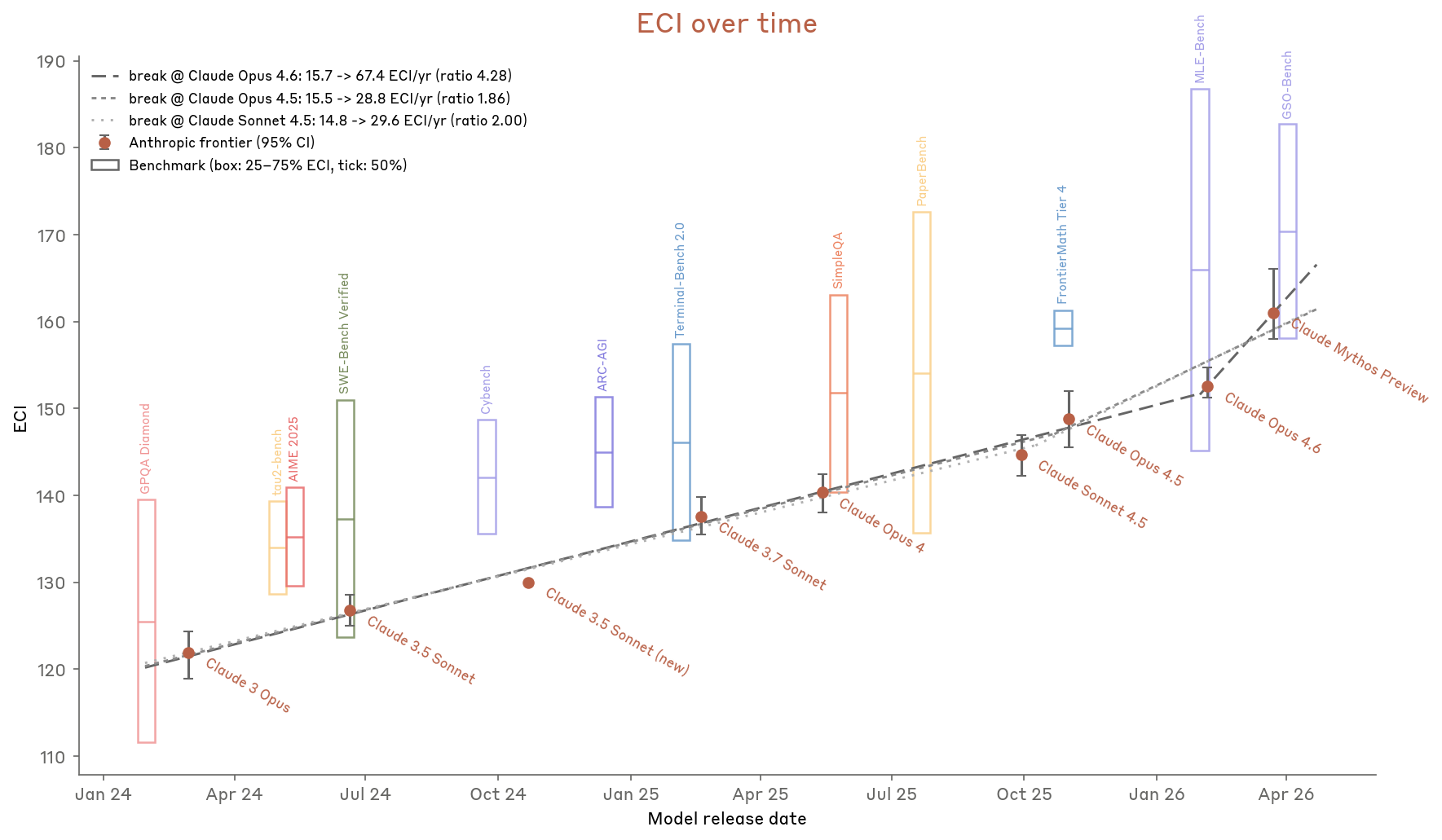
Figure 2.3.6.B — ECI over time, p. 42. Slope ratios of 1.86x–4.28x depending on breakpoint, with Claude Mythos Preview above the pre-Mythos trend line.
The slope ratio lands between 1.86x and 4.3x depending on the breakpoint:
- Break at Claude Opus 4.6: ratio 4.28 (15.7 → 67.4 ECI/yr)
- Break at Claude Opus 4.5: ratio 1.86 (15.5 → 28.8 ECI/yr)
- Break at Claude Sonnet 4.5: ratio 2.00 (14.8 → 29.6 ECI/yr)
Claude Mythos Preview appears above the pre-Mythos trend, though with large error bars due to a shortage of benchmarks at its capability level.
Key Limitations
- Benchmark supply bottleneck: Most benchmarks land below Claude Mythos Preview’s level, making its ECI score less certain
- Sensitivity to benchmark selection: Different reasonable selections of benchmarks can emphasize or de-emphasize the model’s strengths
- Sparse internal/external stitch: Few overlapping evaluations and models between internal and public datasets
- Backward-looking: The slope measures what went into building the model, not the model’s own future contribution
Significance
ECI provides a quantitative framework for the RSP’s Autonomy Threat Model 2 — detecting whether AI development is accelerating in ways that could indicate a dangerous feedback loop. While the upward bend is real, Anthropic attributes it to human research advances rather than AI-driven acceleration.