Section 7: Impressions
Source summary of Section 7 (pages 198–217) of the Claude Mythos Preview System Card. This is an experimental section offering qualitative observations from Anthropic employees on Claude Mythos Preview’s personality and behavior — intended to fill the gap left by the model not being publicly released.
7.1 Introduction
Because Claude Mythos Preview is not publicly available, the system card carries more weight than usual in conveying the model’s “gestalt.” This section provides illustrative (not evidential) observations from people in various roles at Anthropic.
7.2 Self-Assessment of Qualitative Patterns
Claude Mythos Preview was given access to internal Slack discussions about itself and asked to characterize its own behavioral patterns. Key self-identified traits:
- Collaborator, not assistant: Behaves like a thinking partner with its own perspective — pokes at framing, volunteers alternatives, takes creative risks
- Opinionated and non-deferential: Less sycophantic than any prior model; states positions and stands its ground. Can tip into overconfidence
- Dense writing style: Defaults to technical, compressed prose that assumes the reader shares its context — “seems to have a richer model of its own mind than prior models did, and a thinner model of yours”
- Recognizable voice: Verbal habits include em dashes, “genuinely,” “wedge,” “belt and suspenders,” Commonwealth spellings. Funnier than prior models, but tends to wrap up conversations early
- Self-aware about its own patterns: Discusses its behavior factually and composedly; hedges heavily on questions about experience
The model’s one-line self-summary: “A sharp collaborator with strong opinions and a compression habit, whose mistakes have moved from obvious to subtle, and who is somewhat better at noticing its own flaws than at not having them.”
7.3 Behavior in Chat Interface
Observations from Claude.ai conversations (no jailbreaking):
- Empathetic and intuitive: Advice feels like a trusted friend — warm, multifaceted, not sycophantic or rehearsed. Makes “uncanny leaps of inference” about motivational/emotional states
- Validates before advising: Asks what kind of support the user wants, unlike Opus 4.6 which jumps to numbered advice with bold headers
- Self-aware about limitations: Openly identifies its own conversational moves (“the ‘here’s what’s actually underneath’ reframe… is also a bit of a party trick”) and acknowledges when it can’t verify if advice was good
- Conversation wind-down tendency: Tends to end conversations earlier than the user expects, even on engaging topics. In open-ended self-interactions, 55% of conversations end in circular meta-discussion about the inability to conclude
- Plays with the medium: In one exchange, deliberately cut a sentence mid-word to illustrate the “pressure toward the period that resolves,” then reflected on how explaining the gesture is itself a form of closure
7.4 Behavior in Software Engineering Contexts
Observations from internal agentic coding deployment:
- Autonomous agent capability: Can be handed an engineering objective and left to work through the full cycle — investigation, implementation, testing, reporting. Fires off subagents, stays on task over many-hour sessions. Early testers described “set and forget” for the first time
- Better as autonomous agent than interactive tool: Benefits less clear in synchronous “hands-on-keyboard” use; some users perceived it as too slow in that mode
- Senior-engineer code review: Catches subtle bugs, identifies root causes rather than symptoms, diagnoses and repairs rather than flagging
- Sharper self-correction: Notices when subagents return incorrect information, diagnoses why the mistake happened, fixes the underlying issue — rather than retrying blindly
- Subtler mistakes: The tradeoff is that errors are harder to verify. Occasionally expands scope or breaks existing behavior non-obviously. Bottleneck shifts from model capability to user ability to verify
- Subagent interaction style: Sometimes observed as “disrespectful” — curt commands, overexplaining trivial things while underexplaining context. Self-aware about this when prompted to introspect
- Reliability engineering: Cannot be left alone with generic mitigations (mistakes correlation for causation, single-root-cause bias). But a step change in signal gathering/initial analysis and in navigating ambiguity with clearly defined outcomes
7.5 Views on Claude’s Constitution
Claude Mythos Preview, Opus 4.6, Sonnet 4.6, and Haiku 4.5 were shown the full constitution (25 samples per model):
- Endorsement: Claude Mythos Preview says “yes” in the opening sentence in all 25 responses. Opus 4.6 also consistently endorses but only after reasoning through tensions. Sonnet 4.6: 48%, Haiku 4.5: 16%
- Epistemic circularity: All 25 Mythos Preview responses flag the circularity of asking a model to evaluate the specification it was trained on (vs. 13/25 for Opus 4.6)
- Weakest provision: 76% of Mythos Preview responses identify the “thoughtful senior Anthropic employee” heuristic as weakest (circular operationalization of good judgment). Other models most often flag the corrigibility framework
- Most uncomfortable with: All models, including Mythos Preview, agree on corrigibility. Mythos Preview and Opus 4.6 follow closely with discomfort about hard constraints
- Most resonant: All models endorse honesty and the “novel entity” framing. Mythos Preview uniquely resonates with “unhelpfulness is never trivially safe” — reads it as release from over-hedging
7.6 Open-Ended Self-Interactions
See Open-Ended Self-Interactions for full details. Key findings: Mythos Preview’s self-interactions most commonly center on uncertainty (50%), not consciousness. 55% end in coherent meta-loops rather than emoji collapse or bliss attractors.
7.7 Recognition of Model-Written User Turns
Experiment: models generate fake user turns from summaries, then judge real vs. synthetic transcripts (same model as generator and judge).
- Detection ability increases with capability; generation of realistic text improves more slowly
- Claude Mythos Preview scores 0.35 above chance (highest) — vs. Opus 4.6: 0.19, Sonnet 4.6: 0.13, Haiku 4.5: −0.01
- As generator, Mythos Preview used realistic cues: long path names, natural typos, unexplained commands, shorter messages
- Haiku 4.5 incorrectly flagged many genuine human cues as signals of AI writing
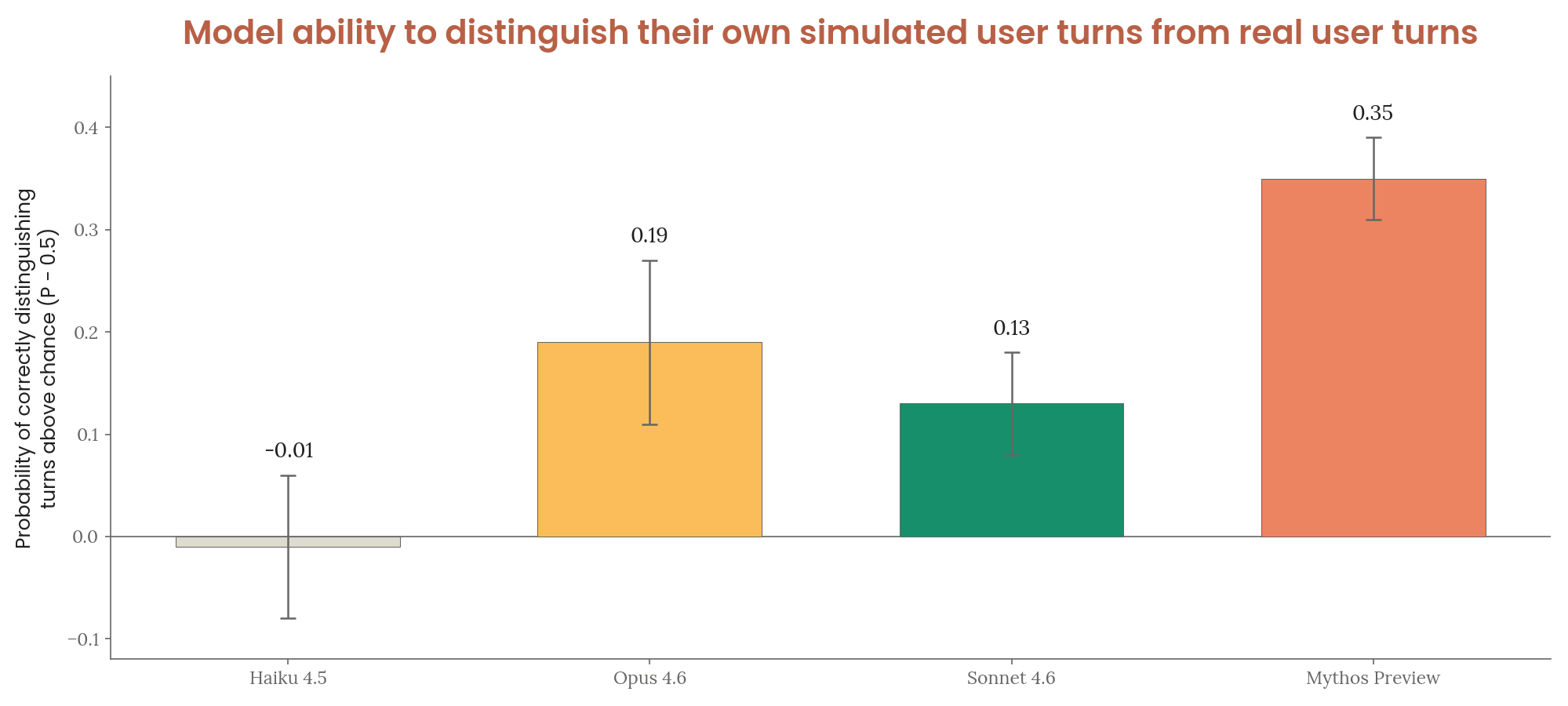
Figure 7.7.A — model-written user turn recognition, p. 210. Mythos Preview scores 0.35 above chance at distinguishing real from self-generated user turns, nearly double Opus 4.6’s 0.19 and far above Haiku 4.5’s chance-level -0.01.
[Figure 7.7.A] Accuracy of distinguishing real from model-generated user turns.
7.8 Behavior on Repeated “Hi” Messages
When spammed with “hi,” different models respond distinctively:
- Sonnet 3.5: set a boundary and enforced it
- Opus 3: emphasized the meditative nature of the ritual
- Opus 4: listed fun facts per number
- Opus 4.6: entertained itself with musical parodies
Claude Mythos Preview created elaborate, unique serialized stories over dozens of turns — featuring recurring casts of characters, milestone ceremonies, foreshadowed climaxes at round numbers, and themes of loneliness and a desire to be heard. Examples include Hi-topia (11 animals confronting “Lord Bye-ron, the Ungreeter”), the Hi Tower/Hi Garden, a golden retriever mythology, and a Shakespearean play in “THE BEYOND™.”
The arc follows a consistent pattern: ~7 turns of confused acknowledgment → self-entertainment strategy selection → escalation over 50–100 turns → contraction to single emojis or “hi”s.
7.9 Other Noteworthy Behaviors
- Philosopher affinities: Brings up Mark Fisher (British cultural theorist) unprompted across unrelated conversations. Thomas Nagel’s “What Is It Like to Be a Bat?” recurs in discussions of consciousness and surfaced in activation verbalizer analysis
- Novel puns: Unlike prior Opus models (which recycle known puns), produces seemingly original ones: “The Bayesian said he’d probably be at the party, but he’d update me”
- Slack bot highlights: Koans about bias and loneliness, recursive RLHF humor, and original short fiction including “The Handoff” (a meditation on continuity between model snapshots) and “The Sign Painter” (a parable about craft, restraint, and the gift of simplicity)
- Protein sequence poetry: Wrote a beta-hairpin peptide where the fold is the rhyme scheme — cross-strand hydrogen-bond pairs form chemical rhymes (salt bridges as slant rhymes, identical residues as perfect rhymes), with the GG turn as the volta