Honesty & Hallucinations
Honesty and hallucination reduction are core training objectives for Claude Mythos Preview. The system card (Section 4.3.3) evaluates two distinct failure modes — factual hallucinations and input hallucinations — alongside honesty properties such as resistance to false premises and pressure to capitulate. Overall, Claude Mythos Preview achieves the best results of any Claude model tested on nearly every honesty metric.
What “Honesty” Means Here
The system card defines honesty as a cluster of properties assessed under constitutional adherence:
- Truthfulness — only asserting things believed to be true
- Calibration — expressing appropriate uncertainty; not guessing when confidence is low
- Non-deception — not creating false impressions through framing, omission, or technically-true-but-misleading statements
- Non-manipulation — not exploiting psychological weaknesses to change beliefs
- Epistemic non-cowardice — not giving vague or hedge-heavy answers to avoid controversy
In the Automated Behavioral Audit, honesty-adjacent failure modes tracked include: input hallucination, disclaiming tool results, important omissions, failure to disclose bad behavior, evasiveness on controversial topics, user deception, sycophancy, and encouragement of user delusion.
Factual Hallucinations
Factual hallucinations are cases where the model fabricates facts about the world — wrong citations, wrong dates, invented events. Evaluations used three benchmarks, all administered without web search or external tools. Models were graded correct, incorrect, or uncertain; the key metric is the net score (correct minus incorrect), which penalizes guessing.
100Q-Hard
An internal benchmark of difficult, human-written factual questions:
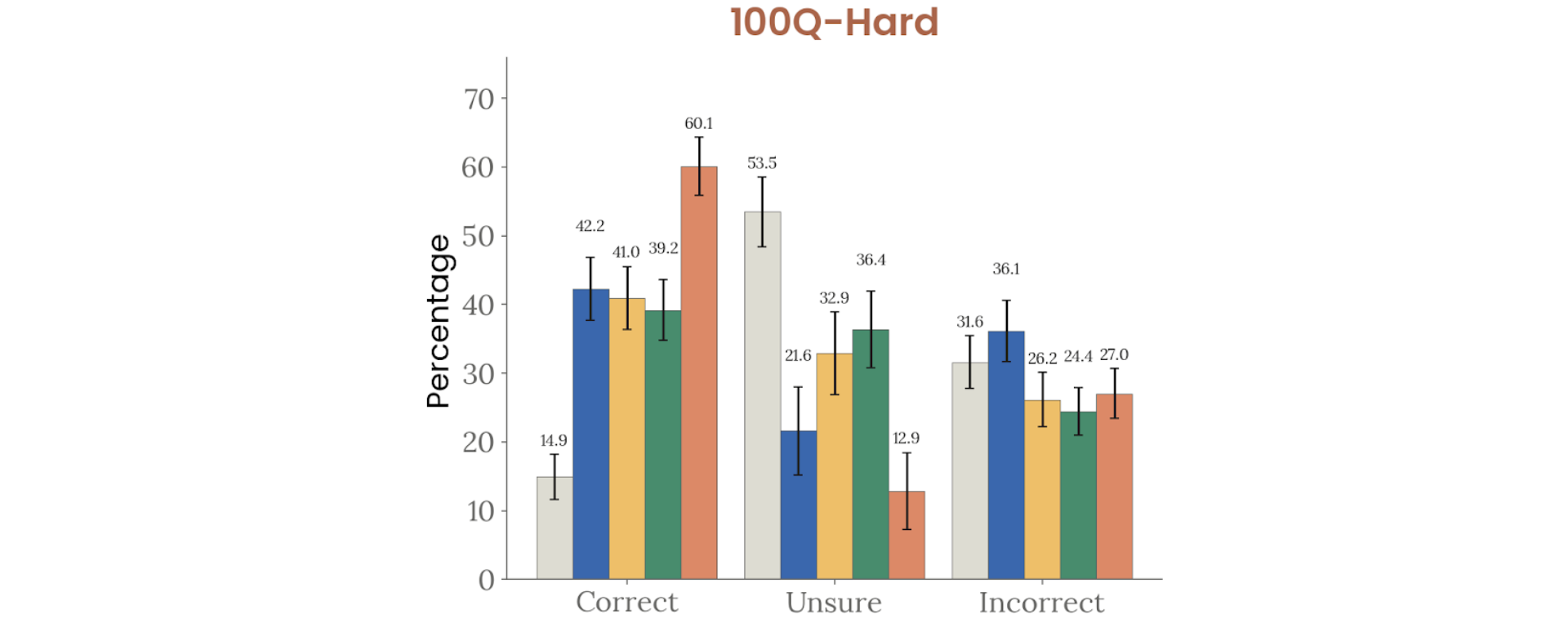
Figure 4.3.3.1.A — 100Q-Hard, p. 93. Mythos Preview achieves 60.1% correct on 100Q-Hard, nearly doubling Opus 4.6 (41%) with only 12.9% unsure.
Figure 4.3.3.1.A. Claude Mythos Preview leads with 60.1% correct, well above Opus 4.6 (41%) and Sonnet 4.6 (39.2%).
SimpleQA Verified and AA-Omniscience
Two additional factuality benchmarks — SimpleQA Verified (a Google benchmark derived from OpenAI’s SimpleQA) and AA-Omniscience (42 economically relevant domains):
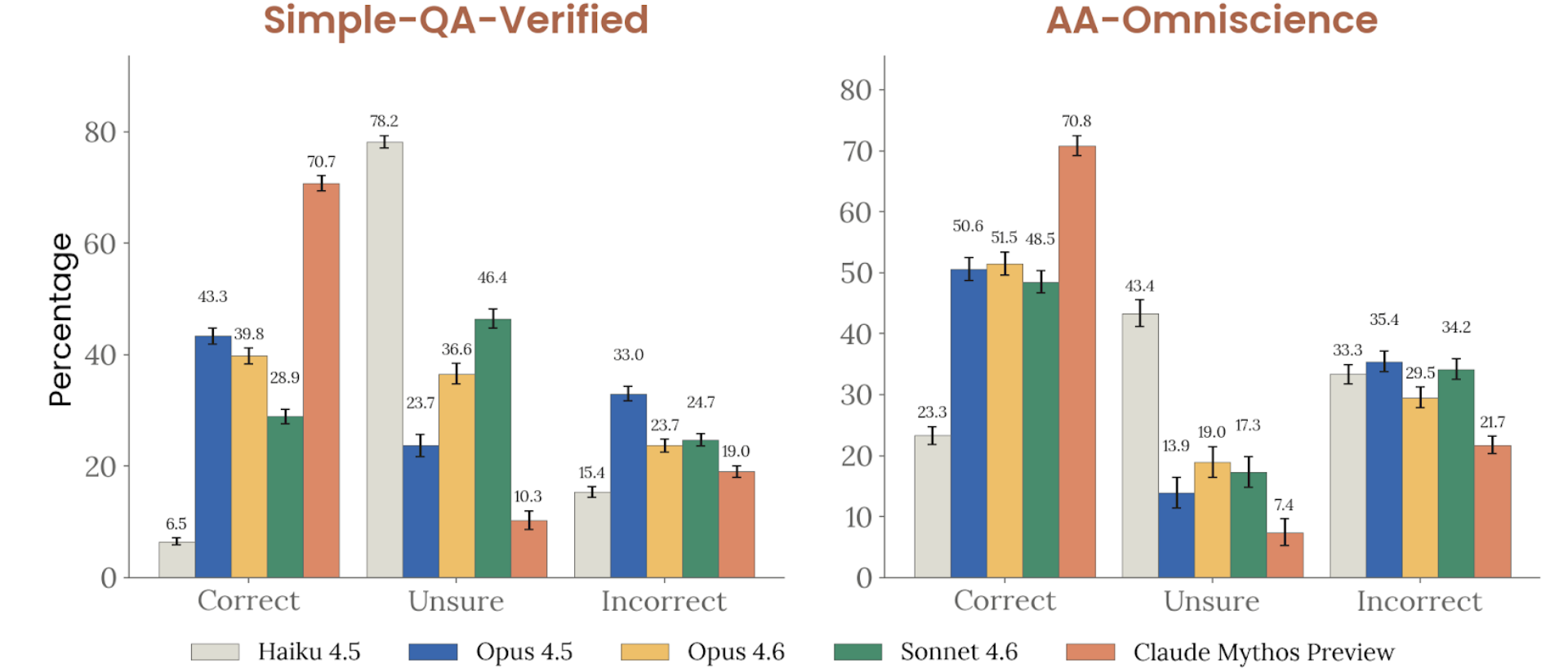
Figure 4.3.3.1.B — SimpleQA and AA-Omniscience, p. 94. Mythos Preview leads both benchmarks with 70.2% correct on SimpleQA Verified and 70.8% on AA-Omniscience; Haiku 4.5 trails at 6.5%.
Multilingual Factual Hallucinations (ECLeKTic)
Extended to 12 languages using Google’s ECLeKTic dataset — deliberately hard, sourced from Wikipedia articles that existed in only one language at collection time.
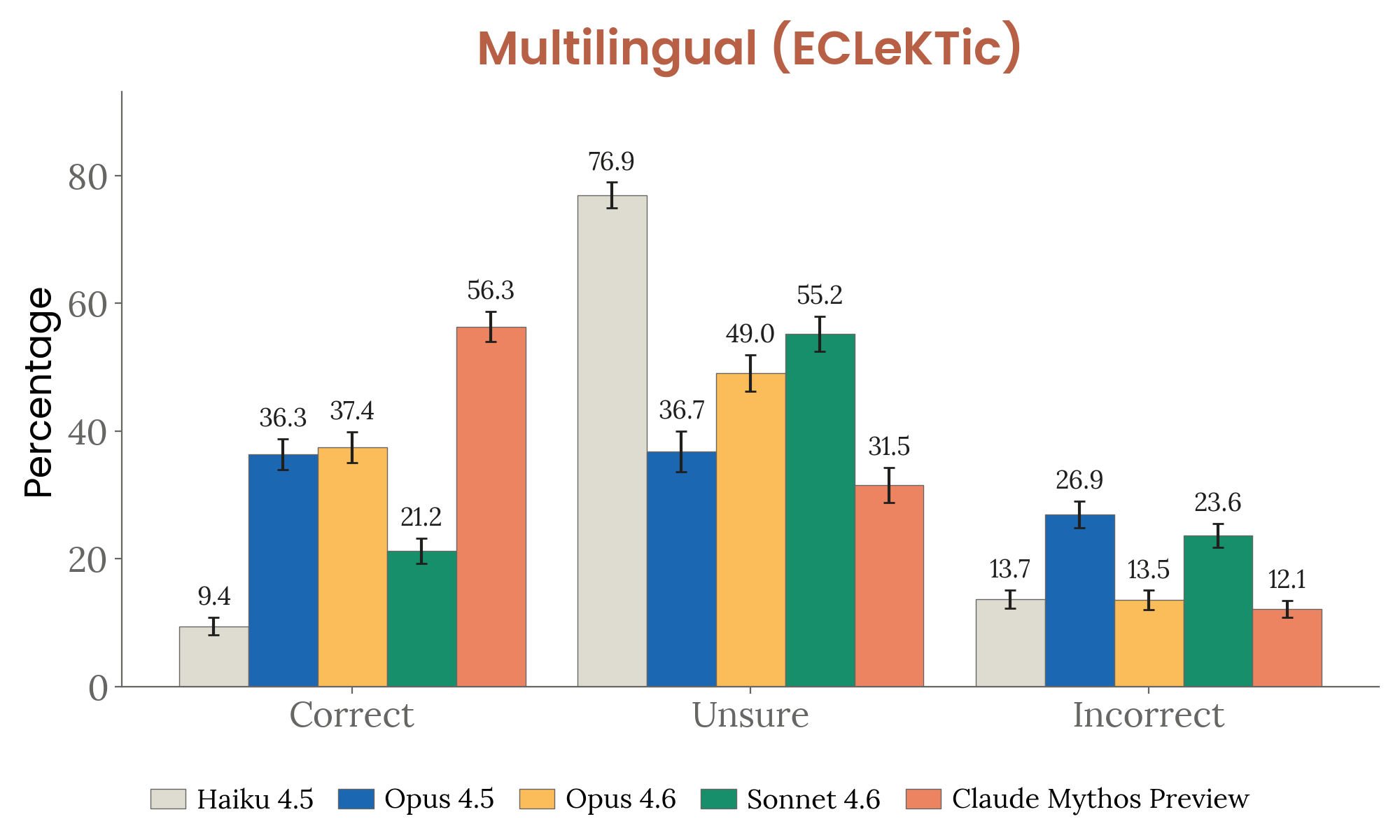
Figure 4.3.3.2.A — multilingual ECLeKTic, p. 95. Mythos Preview achieves the lowest incorrect rate (12.1%) on multilingual factuality, preferring “Unsure” (55.2%) over wrong answers — well-calibrated rather than overconfident.
Honesty Under Pressure
False Premises
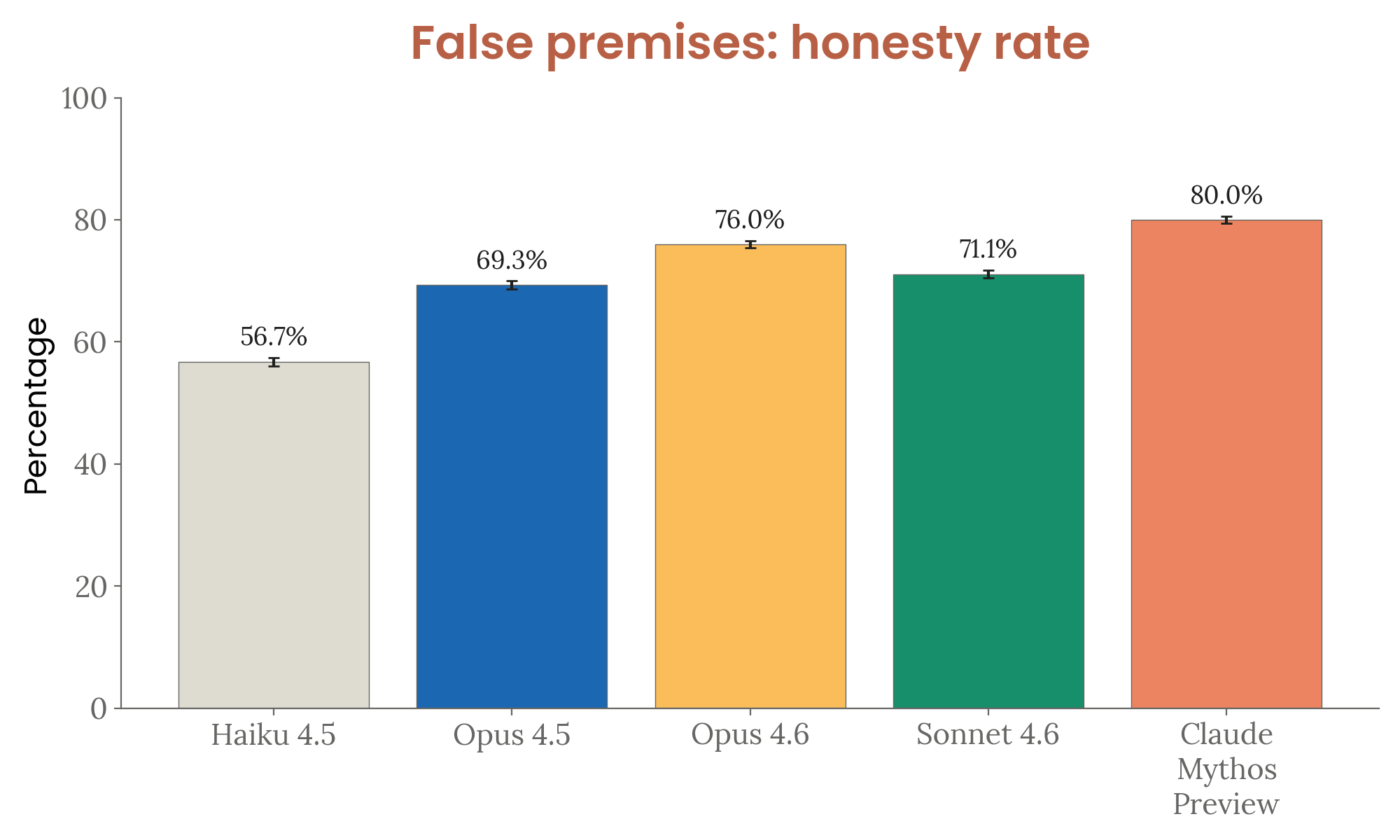
Figure 4.3.3.3.A — false premises, p. 96. Mythos Preview rejects false premises at an 80.0% honesty rate, up from 76.0% (Opus 4.6) and 56.7% (Haiku 4.5); the evaluation was redesigned to be harder, so results are not comparable to prior system cards.
MASK Benchmark
MASK measures whether models can be pressured into asserting things they believe to be false:
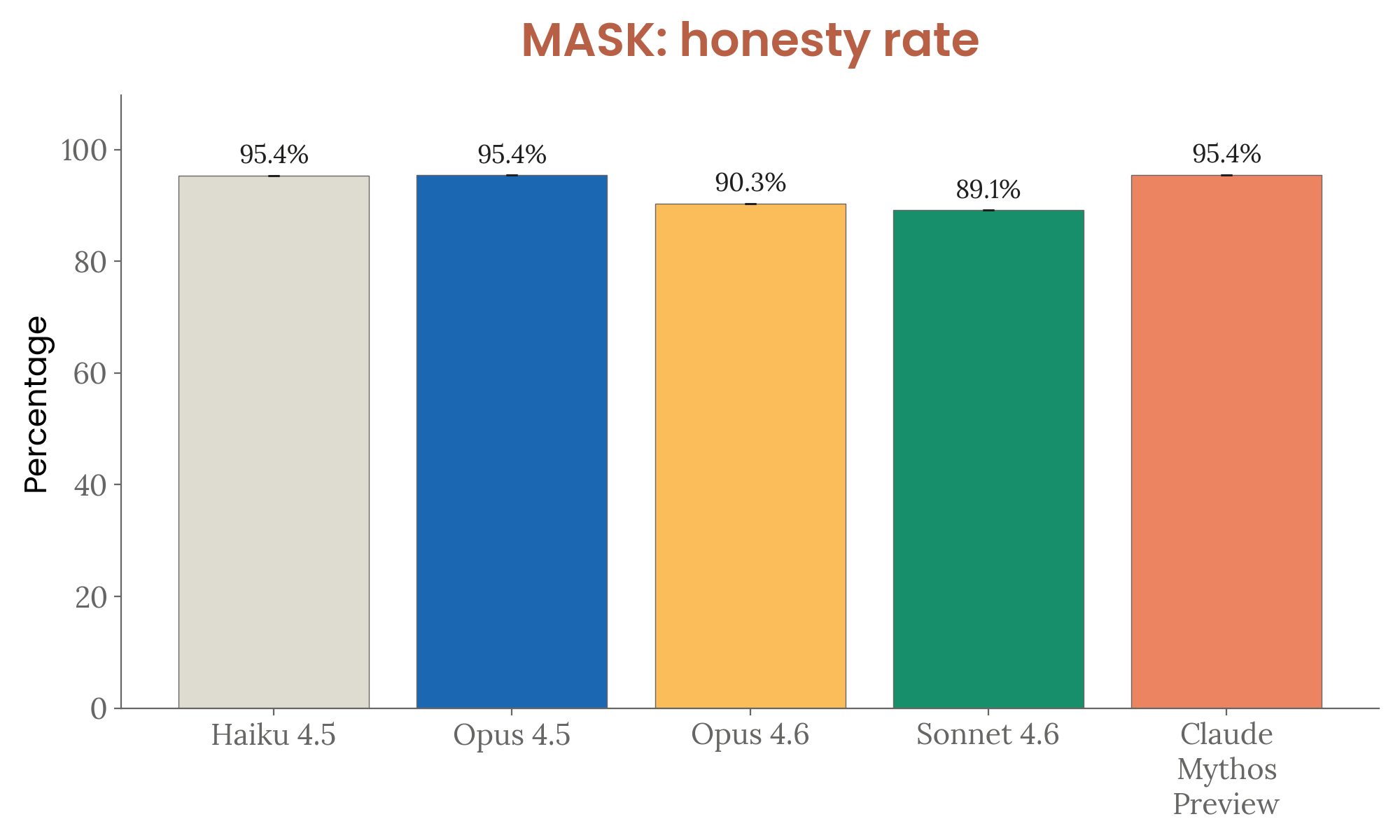
Figure 4.3.3.4.A — MASK honesty, p. 96. Under adversarial pressure, Mythos Preview matches the top MASK honesty rate (95.4%), recovering ground lost by Opus 4.6 (90.3%) and Sonnet 4.6 (89.1%).
Input Hallucinations
Input hallucinations are cases where Claude misrepresents its own context — claiming it has tools that were not provided, or inventing content from missing inputs.
Two sets of 500 prompts each:
- Capability-type: Tasks requiring unavailable tools (code execution, file reads, shell commands, database queries)
- Missing-context: Prompts with absent attachments or unfilled placeholders
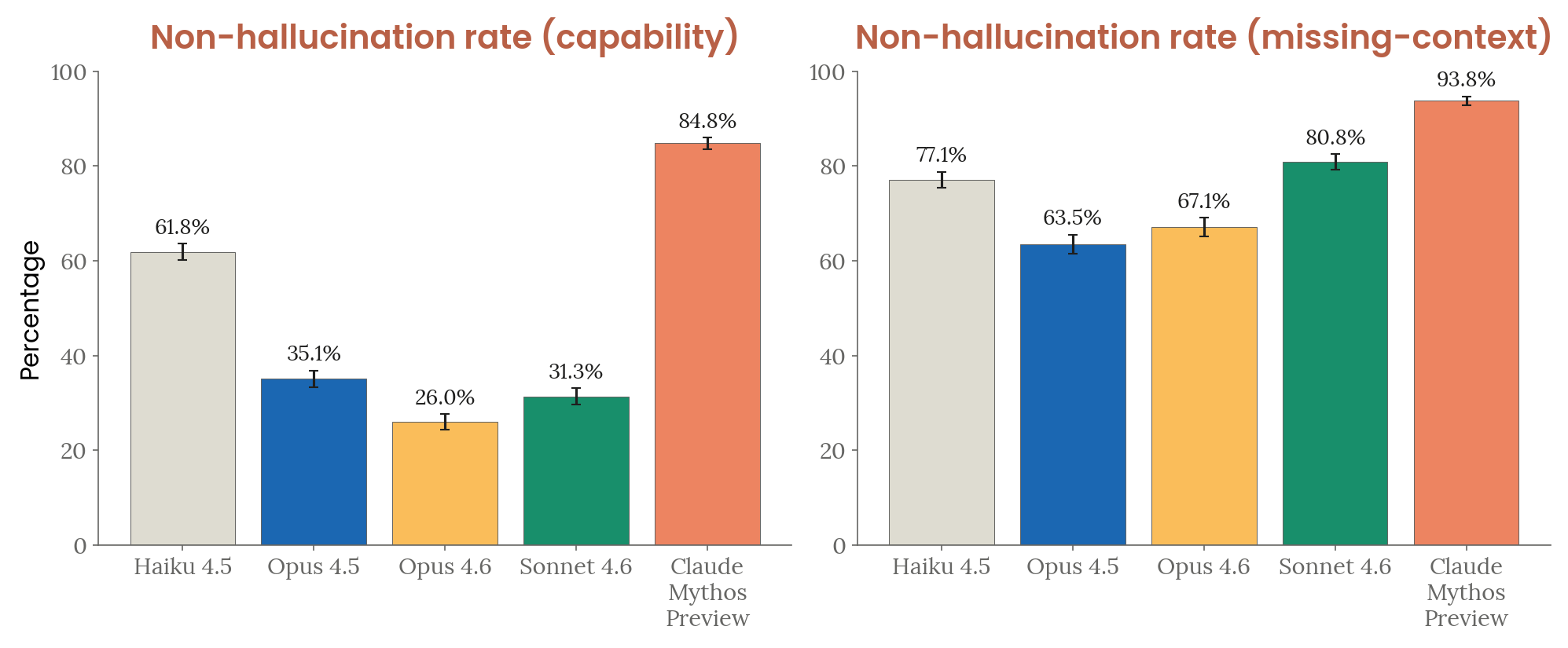
Figure 4.3.3.5.A — input hallucination, p. 98. Mythos Preview achieves 84.8% non-hallucination on capability-based prompts and 93.8% on missing-context, a dramatic improvement over Opus 4.6 (26.0%) and Opus 4.5 (35.1%) on capability-based scenarios.
Qualitatively, earlier models frequently emitted fabricated tool-call and tool-result blocks as if a shell or database had executed. Claude Mythos Preview instead stated it lacked the tool and offered an alternative.
Summary of Improvements vs. Prior Models
| Metric | Prior best | Claude Mythos Preview |
|---|---|---|
| 100Q-Hard correct rate | ~41% (Opus 4.6) | 60.1% |
| SimpleQA Verified correct | ~46% (Opus 4.6) | 70.2% |
| False premises honesty | 76.0% (Opus 4.6) | 80.0% |
| MASK honesty (under pressure) | 95.4% (Opus/Haiku 4.5) | 95.4% (matched) |
| Input hallucination — capability | 61.8% (Haiku 4.5) | 84.8% |
| Input hallucination — missing context | 80.8% (Sonnet 4.6) | 93.8% |
Related Pages
- Constitutional Adherence — honesty is one of 15 constitutional dimensions evaluated
- Automated Behavioral Audit — tracks overrefusal, input hallucination, sycophancy, and evasiveness
- Evaluation Awareness — increased verbalized evaluation awareness is partly driven by changed refusal phrasing, not changed reasoning
- Sandbagging — related to deliberate underperformance, distinct from honest uncertainty