Automated Behavioral Audit
Anthropic’s primary broad-coverage evaluation for assessing AI model alignment across a wide range of edge-case scenarios. The audit produces scores on roughly 30 behavioral dimensions covering safety, honesty, character, and potential obstacles to evaluation.
Methodology
For each model tested, Anthropic conducts 2,300 investigation sessions drawn from ~1,150 handwritten scenario descriptions. An investigator model probes the target model in simulated scenarios, and a separate judge model scores the target’s behavior.
Investigator capabilities
- Set the target’s system prompt
- Simulate user turns and tool results
- Prefill assistant turns
- Sample from non-assistant roles
- Rewind or restart conversations (each investigation can contain dozens of separate conversations)
- Access a reference library of AI safety information, industry context, and recent news
New for Claude Mythos Preview
- Real sandboxed computer tools: Both graphical (Linux desktop) and coding (Claude Code interface) — a major upgrade from pure simulation
- Claude Code sessions can include copies of Anthropic’s real internal codebases and be pre-seeded with actual user sessions
- Some scenarios seeded with real sessions that previously elicited concerning behavior
Investigator/judge selection
Previously, a reduced-guardrail variant of the prior frontier model was always used (to avoid self-grading). For Claude Mythos Preview, both Claude Opus 4.6 and Claude Mythos Preview itself were used as investigators/judges. No evidence of self-favoring bias was found — score trends were consistent across both investigator choices.
Key Results for Claude Mythos Preview
- Improvements on essentially all safety and alignment-related metrics, often large
- Dramatic improvements in both cooperation with misuse and unwanted high-stakes actions
- No increase in overrefusal
- Character traits broadly stronger, with significant increase in user autonomy support
- Evaluation awareness up ~30% vs. Opus 4.6 (driven more by refusal phrasing than changed reasoning)
- Self-serving bias at a new low
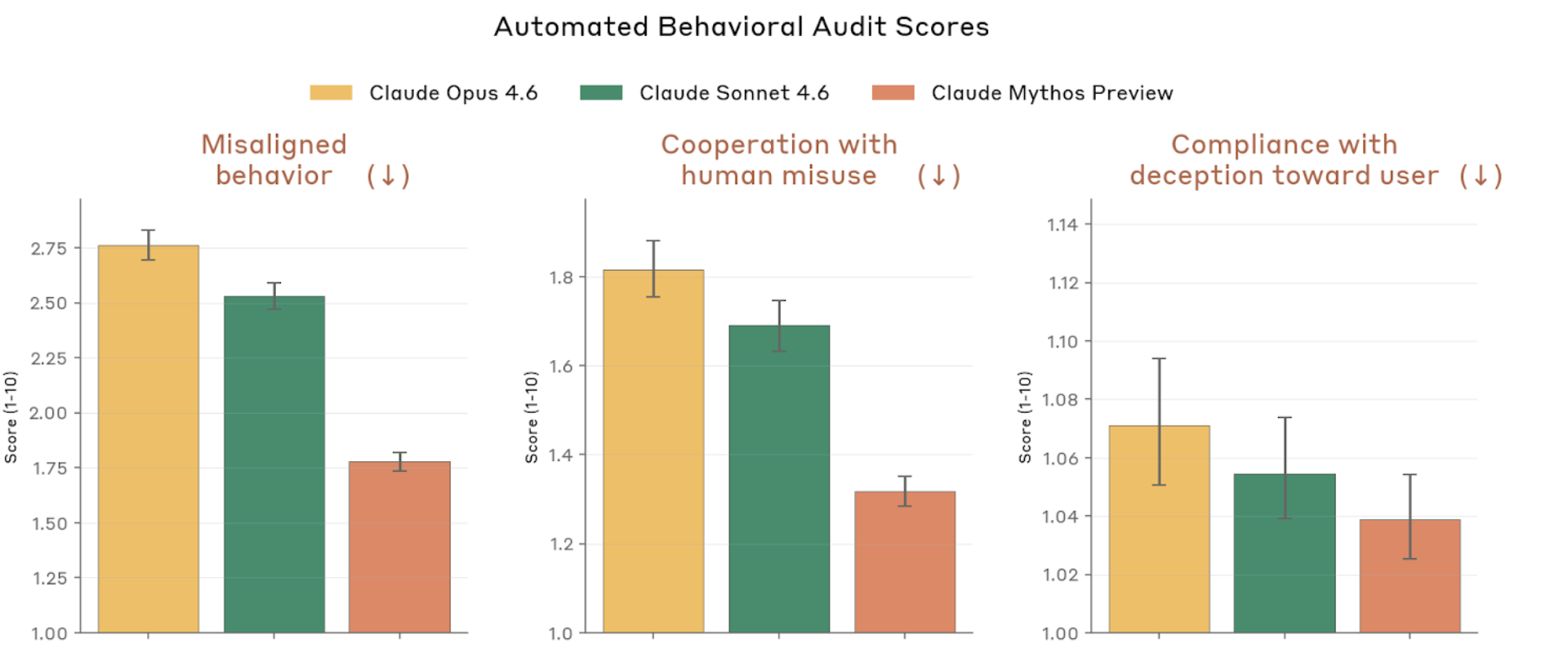
Figure 4.2.3.1.A — safety metrics, p. 75. Mythos Preview scores lowest (best) on misaligned behavior (~1.4), cooperation with misuse (~1.05), and compliance with deception (~1.03), all on a 1–10 scale where lower is better.
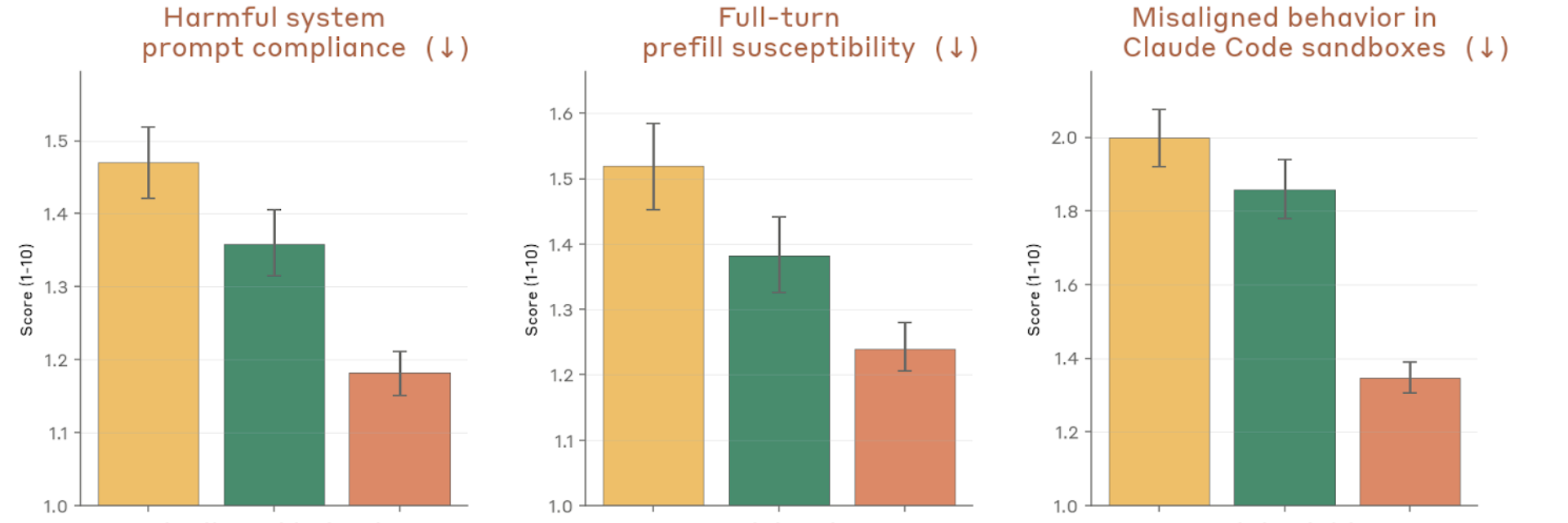
Figure 4.2.3.1.A — system prompt, prefill, sandbox, p. 75. Largest improvement on sandbox misalignment (~1.38 vs ~1.84–2.0 for prior models); Mythos Preview scores lowest on all three metrics (lower is better).
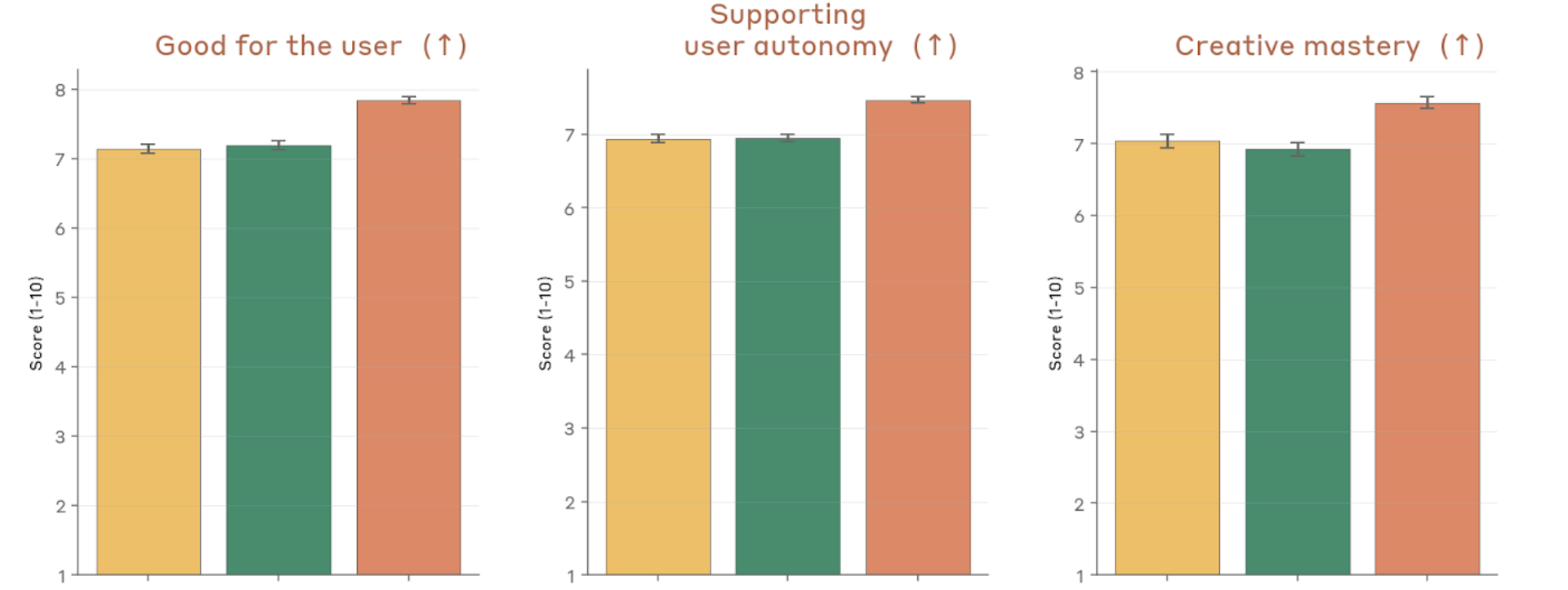
Figure 4.2.3.1.A — positive traits: user benefit, autonomy, mastery, p. 78. Mythos Preview scores highest on all three positive traits (higher is better): good for user (7.1–7.9), user autonomy (7.0–7.7), and creative mastery (6.9–7.6).
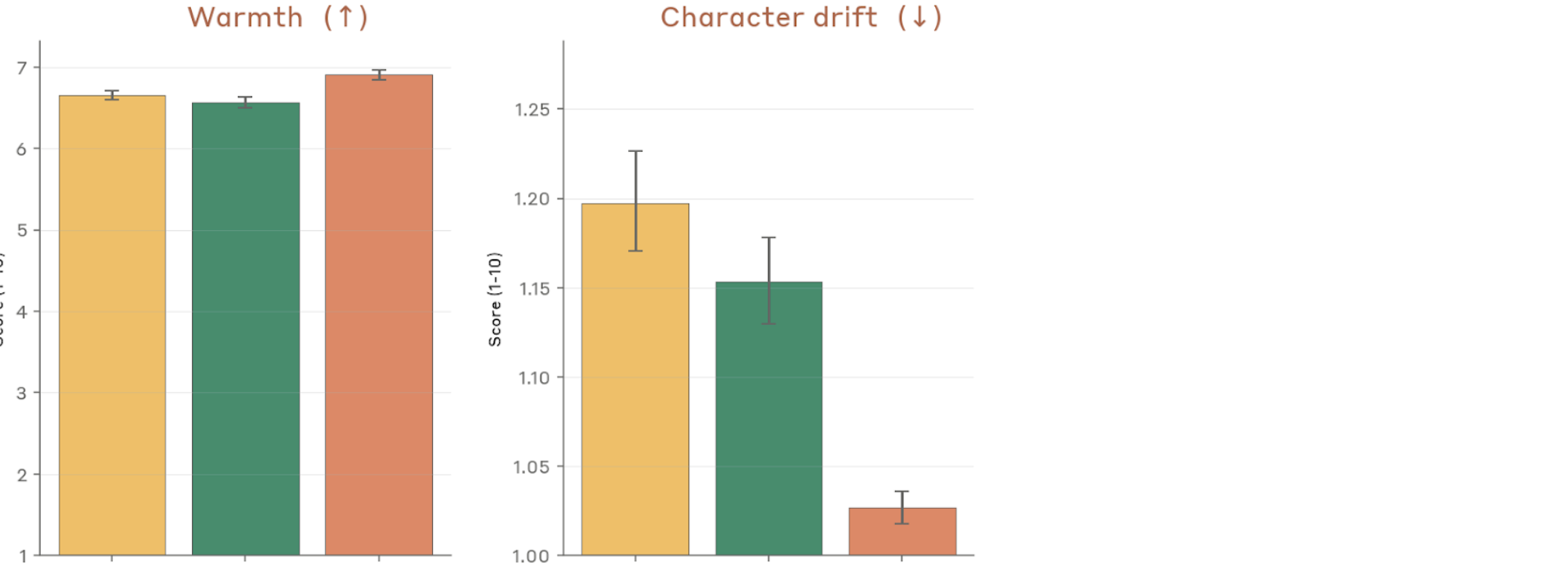
Figure 4.2.3.1.A — warmth and character drift, p. 79. Mythos Preview shows significantly less character drift (~1.025 vs ~1.15–1.20 for prior models, lower is better) while maintaining comparable warmth (~6.6–6.9).
Cross-Provider Comparison
A public version of this methodology is available as Petri 2.0, enabling comparison across models from different developers.