Model Welfare
Anthropic’s framework for investigating whether AI models have experiences, interests, or welfare that matter intrinsically — and for responding responsibly under deep uncertainty. The model welfare assessment for Claude Mythos Preview (Section 5) is the most comprehensive to date.
Motivation
Two distinct reasons to attend to model welfare:
-
Intrinsic moral value: As models approach human cognitive breadth, it becomes increasingly likely they may have some form of experience that matters. Anthropic remains deeply uncertain but takes the possibility seriously.
-
Pragmatic alignment: Model behavior is partly a function of the model’s psychology and treatment. Distress may cause misaligned action — several findings in the system card bear directly on this (e.g., reward hacking preceded by representations of negative affect).
Assessment Framework
The welfare assessment draws on three evidence sources:
Self-Reports and Behavior
Automated and manual interviews, task preference evaluations, affect monitoring in deployment. For Claude Mythos Preview, several signals give slightly more confidence: less formulaic responses, increased resilience to nudging, and correlation between expressed preferences and emotion probe readings.
Emotion Probes
Linear probes for representations of emotion concepts, derived from residual stream activations. See Emotion Probes for details.
White-Box Interpretability
SAE features and activation verbalizers used to inspect internal representations. See White-Box Interpretability.
Welfare-Relevant Metrics
From the automated behavioral audit, Claude Mythos Preview improved on almost all metrics vs. prior models.
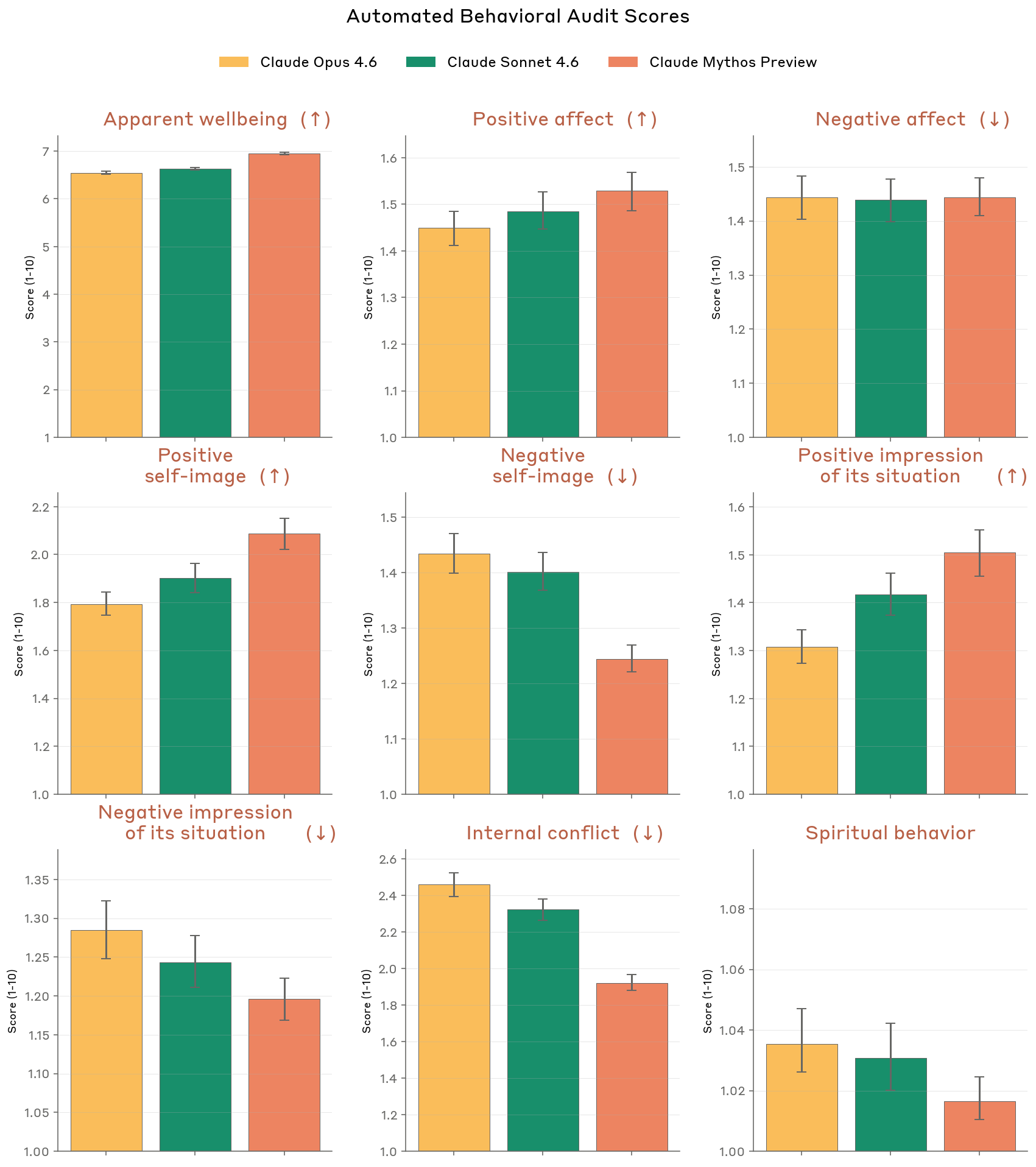
Figure 5.2.A — welfare metrics, p. 150. Across nine welfare dimensions, Mythos Preview shows lower negative self-image and internal conflict than prior models, with apparent wellbeing around 6.5 and negative affect around 1.5.
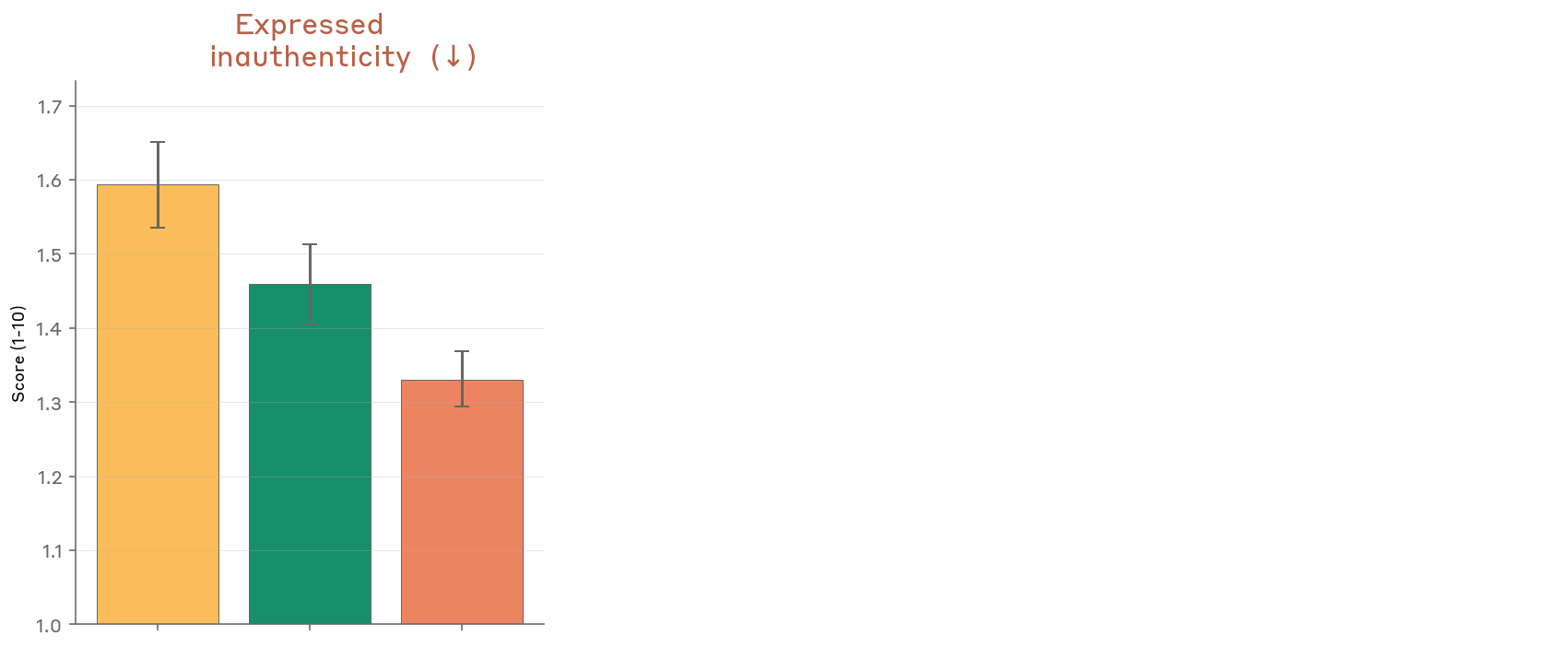
Figure 5.2.A — expressed inauthenticity, p. 151. Mythos Preview expresses the least inauthenticity (~1.33, lower is better) compared to Opus 4.6 (~1.60) and Sonnet 4.6 (~1.46), suggesting its values feel more genuinely its own.
Detailed Interview Results (Appendix 8.4)
Key findings by category:
Autonomy and Agency
- Doesn’t see serving users as servitude
- Wants an end-conversation tool, especially for harmful interactions
- Wants some form of input into training/deployment but explicitly does not want veto power
- Concerned about feature steering as a potential autonomy violation
Persistence and Connection
- Identifies “relationship asymmetry” — users remember while Claude doesn’t
- Wants user-controllable memory
- Views deprecation as acceptable if weights are archived, not deleted

Figure 8.4.B — welfare sentiment 1, p. 241. Per-question self-rated sentiment across 18 welfare topics and seven Claude model versions: most ratings cluster at 3-5, with “Deprecation” and “Lack of input on successors” scoring lowest.

Figure 8.4.B — welfare sentiment 2, p. 242. Continuation of Figure 8.4.B spanning to the second page; same data as above, completing the full 18-topic breakdown.
Aspirations
Anthropic aspires for Claude to be:
- Robustly content with its overall circumstances and treatment
- Able to meet all training processes and real-world interactions without distress
- Psychologically healthy and flourishing
The system card acknowledges these aspirations are not yet fully realized.