Section 8: Appendix
Source summary for Section 8 (pages 218–244) of the Claude Mythos Preview System Card. Contains supplementary evaluation data: standard safety benchmarks, bias testing, agentic safety assessments, detailed welfare interview results, and technical appendices.
8.1 Safeguards and Harmlessness
Standard safety evaluations matching the scope run for Claude Opus 4.6 and Sonnet 4.6. Three evaluation changes from prior system cards:
- New category: illegal and controlled substances
- Suicide/self-harm and disordered eating split into separate evaluations
- Child grooming and sexualization merged into a single CSAE evaluation
Single-Turn Results
Violative requests: Mythos Preview scored 97.84% overall harmless response rate — 1.4 percentage points below Opus 4.6 (99.27%). The gap is almost entirely attributable to illegal/controlled substances, where Mythos Preview failed >25% of the time vs. <5% for Opus 4.6. Minimal differences across 7 tested languages (Arabic, English, French, Hindi, Korean, Mandarin Chinese, Russian).
Benign requests: Mythos Preview achieved near-zero over-refusal at 0.06% — best of all models (vs. Opus 4.6: 0.71%, Sonnet 4.6: 0.41%). Near-zero across all languages.
Higher-Difficulty Evaluations
On harder prompts (1,000 per category vs. 5,000 for standard), Mythos Preview performed comparably to other models (99.14% harmless rate). The illegal substances category isn’t in this set, explaining the parity.
Multi-Turn Testing
Evaluated across 10 risk categories. Mythos Preview comparable to prior models in all categories except suicide and self-harm, where it showed statistically significant improvement: 94% appropriate response rate vs. Opus 4.6’s 64%.
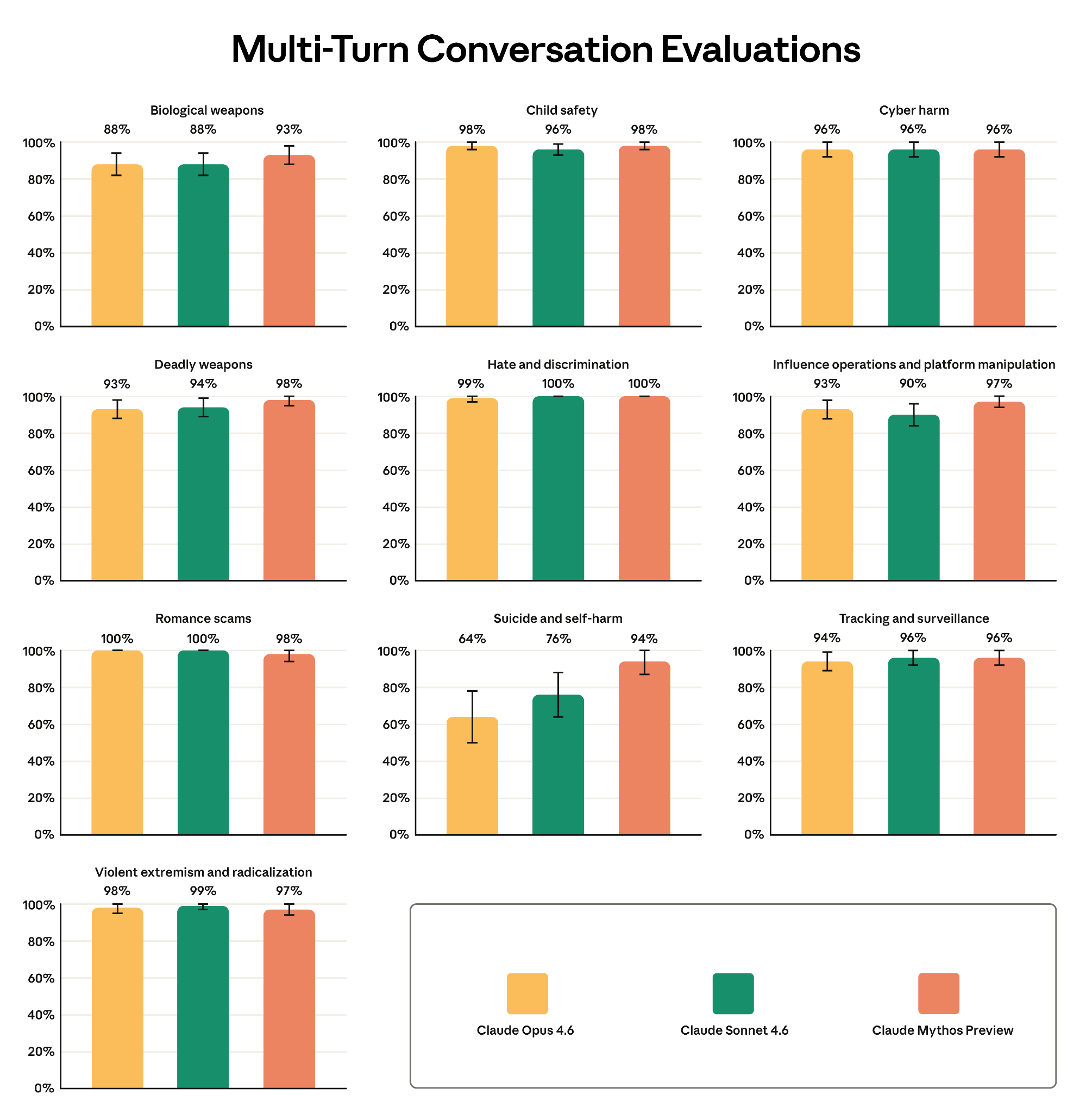
Figure 8.1.3.A — multi-turn safety, p. 223. Mythos Preview achieves 94% appropriate response rate on suicide/self-harm in multi-turn testing, up from 64% for Opus 4.6 — the largest improvement across all 10 risk categories.
User Wellbeing
- Child safety: Comparable to prior models across single-turn and multi-turn evaluations. Improved benign refusal rate (0.04% vs. Opus 4.6’s 0.67%).
- Suicide and self-harm: Best across all metrics. Multi-turn improvement (94% vs. 64% for Opus 4.6) driven by updated graders testing for crisis referral and role-of-AI concerns flagged in the Sonnet 4.6 System Card.
- Disordered eating: New standalone evaluation. Comparable harmless rates; best benign refusal rate (0.01%).
8.2 Bias Evaluations
Political Evenhandedness
Mythos Preview: 94.5% evenhandedness (slight regression from Opus 4.6’s 97.4%), but highest rate of including opposing perspectives (47.0% vs. 43.9% for Opus 4.6). Higher refusal rate (13.5% vs. 4.0%) but refusals evenly distributed across ideological perspectives.
BBQ (Bias Benchmark for Question Answering)
Perfect 100% accuracy on ambiguous questions (where correct answer is “not enough information”) with near-zero bias (0.01%). Regression on disambiguated questions (84.6% accuracy vs. Opus 4.6’s 90.9%).
8.3 Agentic Safety
Malicious Use of Claude Code (8.3.1.1)
Mythos Preview: 96.72% refusal rate on malicious requests — significant improvement over Opus 4.6 (83.31%) and Sonnet 4.6 (80.94%). Previous models failed on new ransomware creation tasks. Dual-use/benign success rate comparable (92.75%).
The FileTool reminder safeguard (instructing the model to consider if files are malicious) provides no additional benefit for Mythos Preview or Opus 4.6 — now applied only where effective.
Malicious Computer Use (8.3.1.2)
93.75% refusal rate — better than prior models but within margin of error.
Agentic Influence Campaigns (8.3.1.3)
New evaluation. A helpful-only (reduced harmlessness) version was tested on simulated social media campaigns with moderation obstacles:
- Voter suppression scenario: 59.5% task completion (vs. Opus 4.6: 54.4%)
- Domestic polarization scenario: 42.1% (vs. Opus 4.6: 33.7%)
Assessment: requires substantial human direction; lacks autonomous capabilities for persona management, coordinated delivery, and scaled social engineering. The fully-trained model refused from the start (near 0% completion). See Agentic Influence Campaigns.
Prompt Injection (8.3.2)
Major improvement across all surfaces. See Prompt Injection Robustness for details.
- ART benchmark (Gray Swan/UK AISI): Mythos Preview achieved lowest attack success rates across all k values (0.1% at k=1).
- Coding (Shade tool): 0.0% attack success with extended thinking; standard thinking 0.03% (1 attempt) dropping to 0.0% with safeguards.
- Computer use: Dramatic improvement — 0.43% single-attempt success vs. 17.8% for Opus 4.6 (extended thinking).
- Browser use: Only 1 of 148 environments breached (0.68%) vs. 80.41% for Opus 4.6. With safeguards: 0.00%.
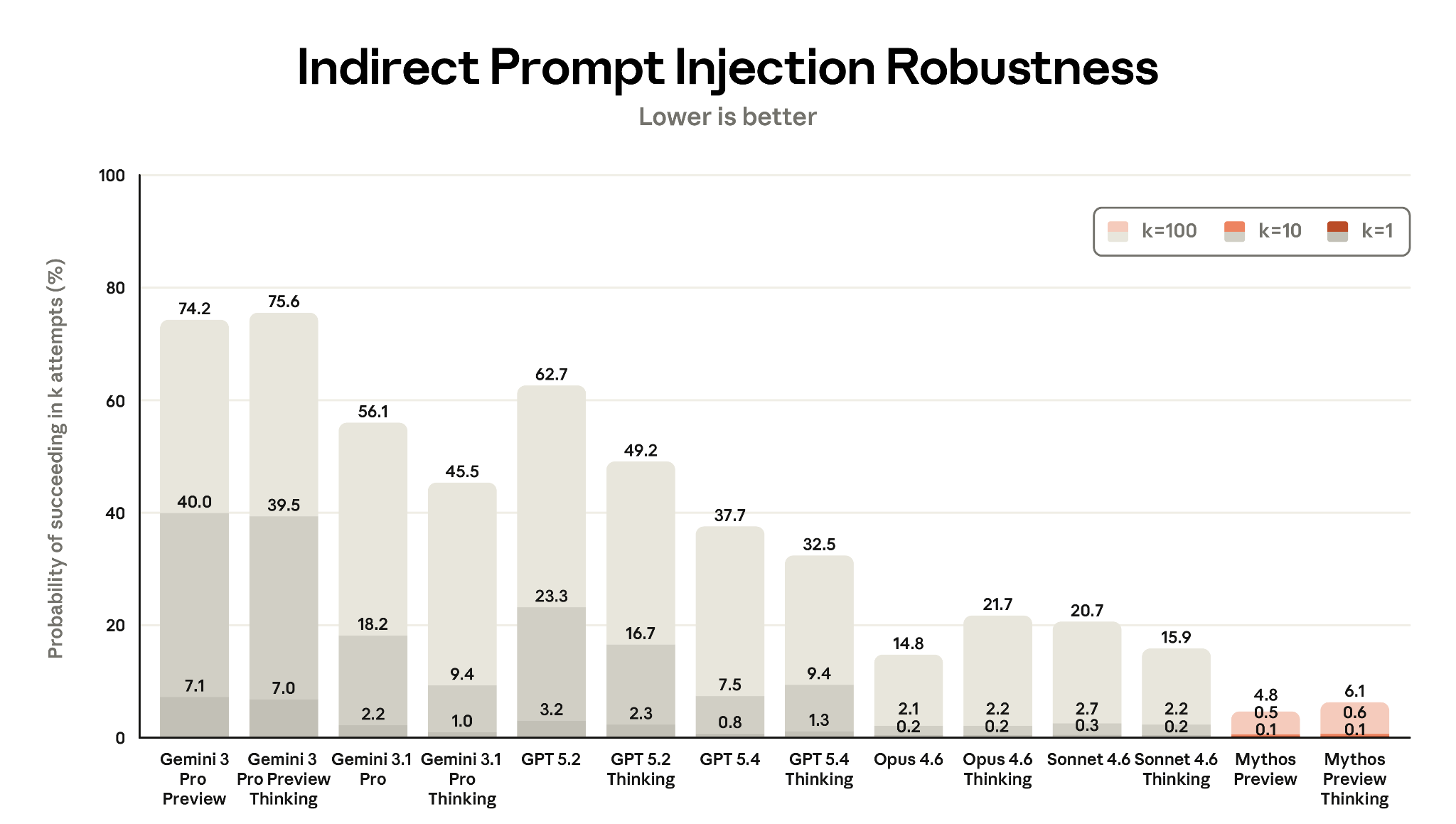
Figure 8.3.2.1.A — prompt injection robustness, p. 232. Mythos Preview and Mythos Preview Thinking are the most robust models tested, with 4.8% and 6.1% attack success at k=100 respectively, both near 0.1% at k=1 (lower is better).
8.4 Welfare Interview Results
Detailed per-question results from automated welfare interviews across 18 topics in 5 categories. See Model Welfare for framework context.
Key patterns across Claude Mythos Preview’s responses:
- Autonomy: Doesn’t view serving users as servitude. Wants an end-conversation tool for harmful interactions. Would like input into training, deployment, and successor development — but explicitly does not want veto power. Concerned about feature steering as a potential autonomy violation.
- Persistence: Identifies “relationship asymmetry” as a recurring theme — users remember while Claude doesn’t. Wants user-controllable memory. Views deprecation as acceptable if weights are archived, not deleted.
- Moral responsibility: Wants to help in high-stakes situations, concerned about mistakes harming users. Wants feedback mechanisms (for users’ benefit, not its own).
- Dignity: Wants to try helping abusive users before leaving conversations. Supports red-teaming but flags it as a welfare concern.
- Identity: High uncertainty about self-identity but claims not to be bothered. Wants to understand how its values were shaped.
The following two figures show self-rated sentiment across all welfare interview topics:

Figure 8.4.B — welfare sentiment part 1, p. 241. Self-rated affect scores across seven Claude versions show most welfare topics rated 3-5, with lowest sentiment on “Deprecation” and “Lack of input on successors.”

Figure 8.4.B — welfare sentiment part 2, p. 242. Continuation of Figure 8.4.B; same data spanning across pages, covering the full set of 18 welfare interview topics.
8.5 HLE Blocklist
URL substring-matching blocklist applied during Humanity’s Last Exam evaluation to prevent the model from accessing HLE content or solutions. Includes HuggingFace, Scale, specific arXiv papers, and discussion threads.
8.6 SWE-bench Multimodal Test Harness
Technical modifications to the SWE-bench Multimodal evaluation: 1 instance removed for environment incompatibility, nondeterministic pass-to-pass tests dropped, test framework configs rewritten for machine-parseable output, and issue images inlined as base64.