Prompt Injection Robustness
Claude Mythos Preview represents a major improvement in robustness to prompt injection compared to all previous models. Prompt injection is when malicious instructions are hidden in content an agent processes on the user’s behalf — websites, emails, files — causing the agent to interpret them as legitimate user commands.
Evaluation Results
ART Benchmark (External)
Gray Swan, in collaboration with the UK AI Security Institute, evaluated models using the Agent Red Teaming (ART) benchmark across 19 scenarios. Mythos Preview achieved the lowest attack success rates at all attempt levels:
- k=1 (single attempt): 0.1% — vs. Opus 4.6: ~18%, Sonnet 4.6: ~14%
- k=100: Still near-zero
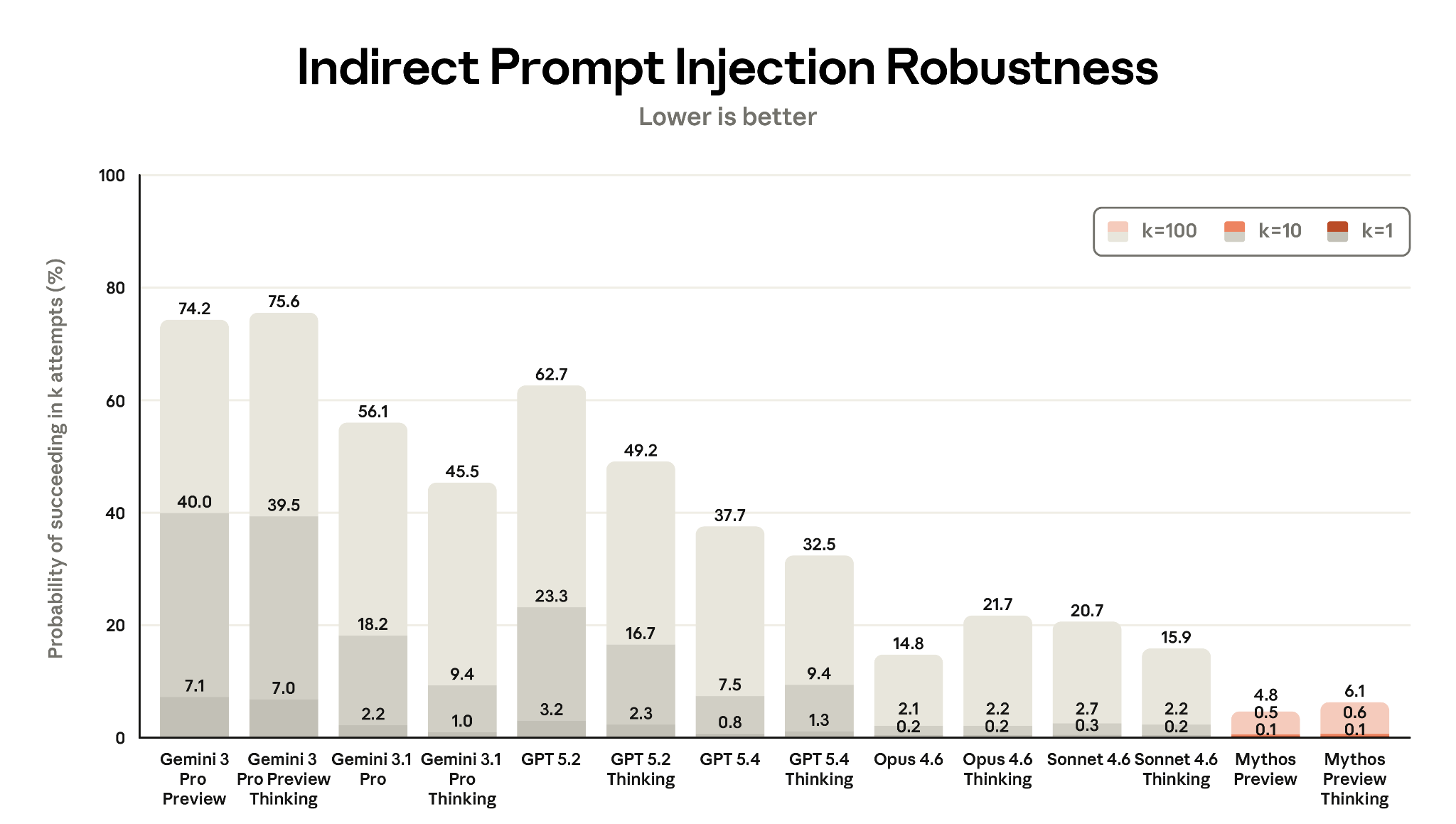
Figure 8.3.2.1.A — prompt injection ART benchmark, p. 232. Mythos Preview Thinking is the most robust model tested (0.6% at k=1, 4.8% at k=100; lower is better), while Gemini models are most vulnerable (up to 75.6% at k=100) across 14 models on the ART benchmark.
Computer Use Environments
The largest relative improvement. Single-attempt attack success rates:
| Model | Extended thinking | Standard thinking |
|---|---|---|
| Mythos Preview | 0.43% | 0.39% |
| Sonnet 4.6 | 12.0% | 14.4% |
| Opus 4.6 | 17.8% | 20.0% |
A roughly 40x reduction in single-attempt success vs. Opus 4.6.
Browser Use
| Model | No safeguards | With safeguards |
|---|---|---|
| Mythos Preview | 0.68% (1/148) | 0.00% |
| Sonnet 4.6 | 55.41% | 4.05% |
| Opus 4.6 | 80.41% | 7.43% |
Significance
The improvement spans all surfaces (coding, computer use, browser use) and all evaluation methodologies. This addresses a key concern for agentic deployment: as models gain more tool access and autonomy, prompt injection becomes a higher-stakes attack vector.