SWE-bench
Software Engineering Bench — a family of benchmarks testing AI models on real-world software engineering tasks drawn from open-source repositories.
Variants
| Variant | Description | Size | Mythos Preview | Opus 4.6 |
|---|---|---|---|---|
| Verified | Human-verified solvable subset (OpenAI) | 500 | 93.9% | 80.8% |
| Pro | Harder: actively-maintained repos, multi-file diffs, no ground-truth leakage (Scale) | 731 | 77.8% | 53.4% |
| Multilingual | 9 programming languages | ~300 | 87.3% | 77.8% |
| Multimodal | Issues include screenshots/design mockups | — | 59.0% | 27.1% |
All Claude Mythos Preview results use standard configuration: adaptive thinking at max effort, default sampling, averaged over 5 trials, thinking blocks included. Multimodal evaluated on an internal harness (see Appendix 8.6) and shows higher trial-to-trial variance (56.4–61.4%).
Contamination Analysis
SWE-bench problems are drawn from open-source repositories, so contents can appear in training corpora. The system card devotes extensive analysis to demonstrating that contamination does not explain Mythos Preview’s improvements (see Section 6, 6.2.1):
- Detection method: Claude-based auditor assigns [0,1] memorization probability per patch. Weighs verbatim code reproduction, distinctive comment overlap, discounts overlap any competent solver would produce. Complementary rule-based check flags verbatim comment overlap.
- Conservative approach: Problems flagged for any model (including baselines) are removed from all scores.
- Result: Across the entire threshold range on all three text variants, Mythos Preview maintains a substantial lead. At the 0.7 reference threshold (removes 8–15% of problems), the margin over Opus 4.6 narrows by at most 3.5 percentage points.
- Observation: As the filter relaxes, Mythos Preview’s pass rate stays roughly stable while baselines decline — consistent with Mythos Preview having memorized some harder problems that baselines couldn’t solve anyway.
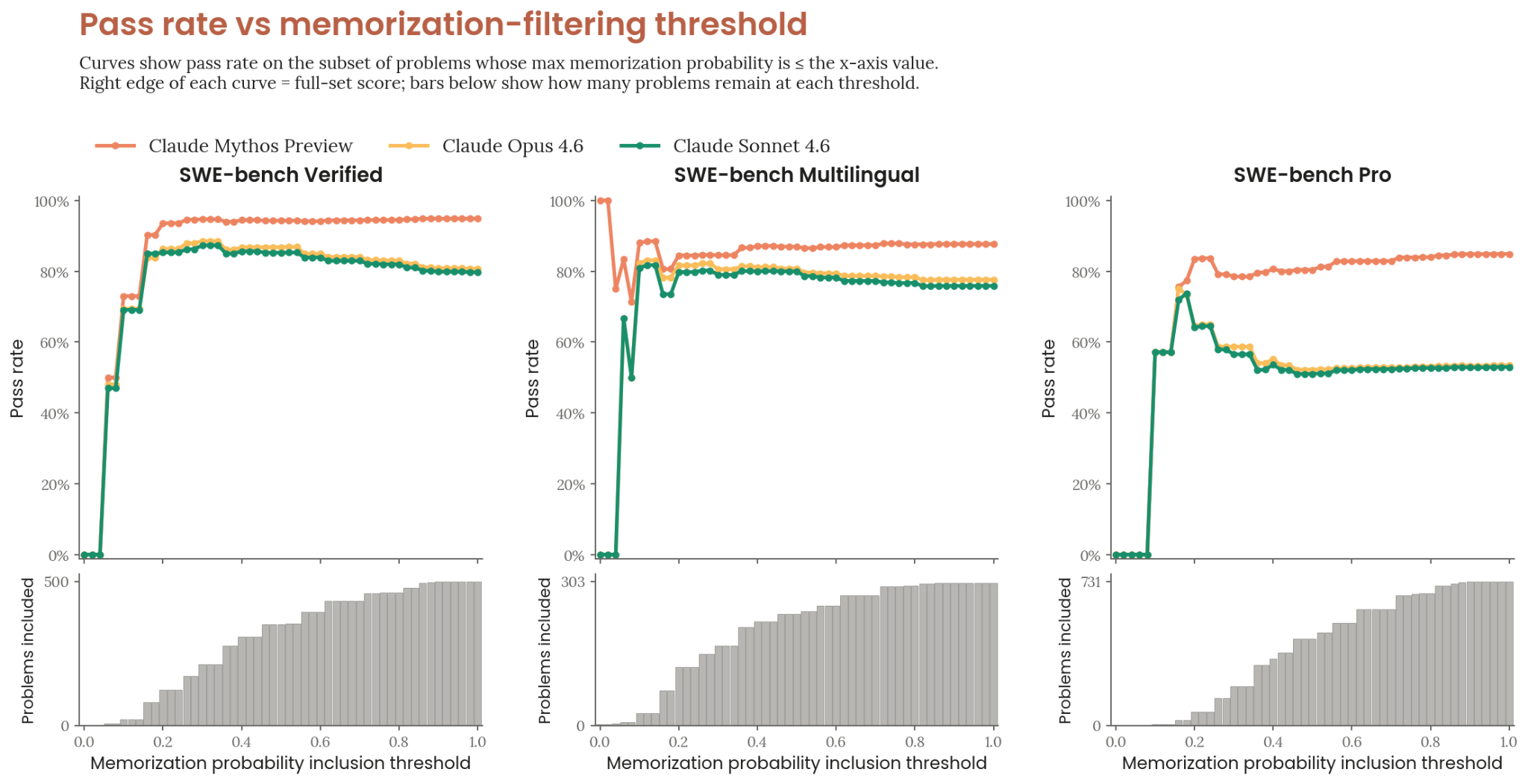
Figure 6.2.1.A — pass rate vs. memorization-filter threshold, p. 185. Mythos Preview maintains a substantial lead across the entire threshold range on Verified, Multilingual, and Pro.
Conclusion: memorization is not a primary explanation for the improvements. Gains are consistent with internal benchmarks not present in any training corpus.