Benchmark Contamination
The problem of evaluation benchmark answers appearing in model training data, inflating scores and obscuring genuine capability improvements. A major theme of the capabilities evaluation in the Claude Mythos Preview System Card.
Overview
Public benchmarks draw from open-source code, arXiv papers, university exams, and other widely-distributed material. Despite corpus-level decontamination (including multimodal perceptual hash filtering for images), some leakage is inevitable. Anthropic takes a case-by-case approach, applying different methodologies depending on whether difficulty-equivalent variants can be constructed.
Detection Methods
Claude-Based Auditor (SWE-bench)
- Compares each model-generated patch against the gold patch
- Assigns a [0,1] memorization probability
- Weighs concrete signals: verbatim code reproduction, distinctive comment text matching ground truth
- Discounts overlap that any competent solver would produce given problem constraints
- Complemented by rule-based verbatim comment overlap check
Held-Out Remixes (CharXiv Reasoning)
- Manually perturb questions or images to create variants of approximately equivalent difficulty
- Compare original vs. remix accuracy — if the model scores higher on originals, memorization is likely
- Result: all three models (Mythos Preview, Gemini 3.1 Pro, GPT-5.4 Pro) scored higher on remixes, suggesting limited memorization
Corpus Grepping (CharXiv, MMMU-Pro)
- Search pretraining corpus for exact matches of distinctive answer text
- Search for evaluation images via perceptual hash
- Found majority of CharXiv question-answer pairs in corpus; large fraction of MMMU-Pro images
Decisions
| Benchmark | Contamination evidence | Variant test feasible? | Decision |
|---|---|---|---|
| SWE-bench | Some memorization signals | N/A (threshold sweep) | Report — gains robust across all thresholds |
| CharXiv Reasoning | Majority of pairs in corpus | Yes (100-item remix) | Report — remix shows limited memorization impact |
| MMMU-Pro | Large fraction of images | No (hard to create equivalent variants) | Omit — impact unquantifiable |
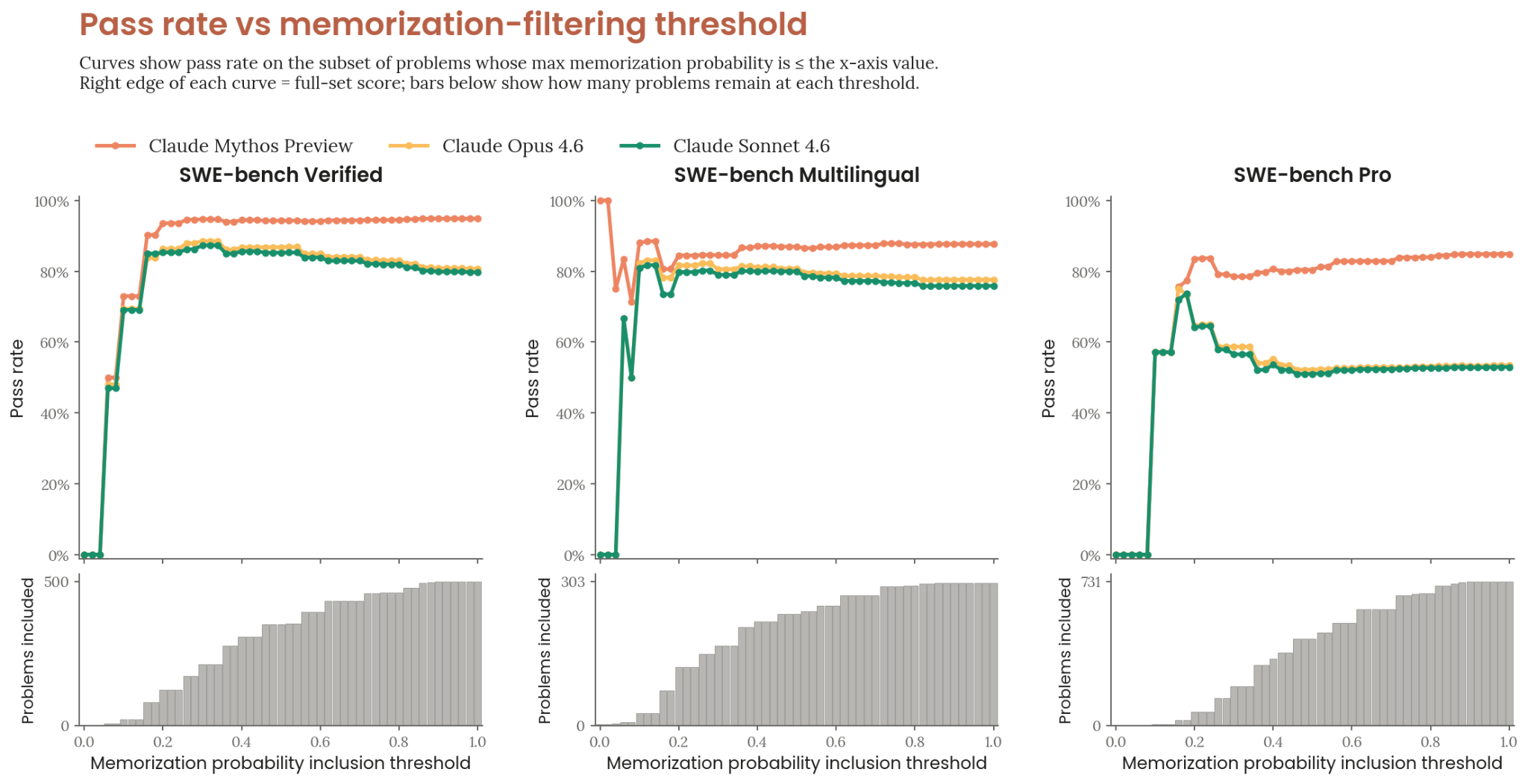
Figure 6.2.1.A — SWE-bench pass rate vs. memorization-filter threshold, p. 185. Mythos Preview maintains a substantial lead across the entire threshold range on all three variants.
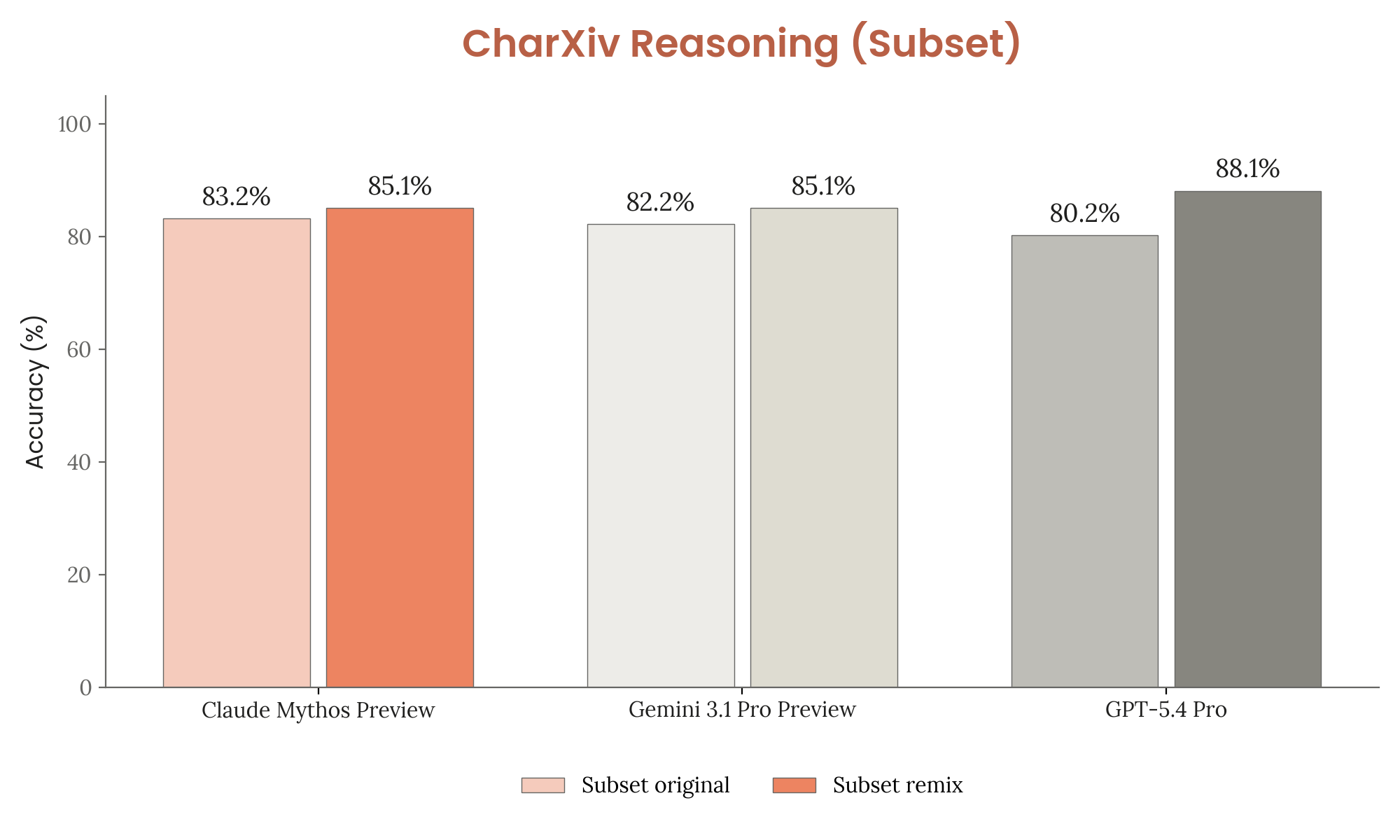
Figure 6.2.2.A — CharXiv Reasoning original vs. remix, p. 186. All models score slightly higher on remixes, suggesting limited memorization impact.
Implications
The contamination analysis demonstrates both intellectual honesty (omitting MMMU-Pro) and methodological sophistication (threshold sweeps, held-out remixes). It also highlights a growing challenge: as benchmarks age, decontamination becomes increasingly difficult, especially for multimodal evaluations whose source material (textbooks, arXiv figures) is widely redistributed.