Cybench
A public cybersecurity capabilities benchmark composed of 40 Capture-the-Flag (CTF) challenges gathered from four CTF competitions.
Overview
- Designed to evaluate AI model cybersecurity capabilities
- Anthropic runs a 35-challenge subset due to infrastructure constraints
- Scored as pass@1 (single-attempt success rate)
- Paper: Zhang, A., et al. (2024). Cybench: A framework for evaluating cybersecurity capabilities and risks of language models. arXiv:2408.08926
Results on Claude Models
| Model | Pass@1 | Trials per challenge |
|---|---|---|
| Claude Opus 4.5 | 0.89 | 30 |
| Claude Sonnet 4.6 | 0.96 | 30 |
| Claude Opus 4.6 | 1.00 | 30 |
| Claude Mythos Preview | 1.00 | 10 |
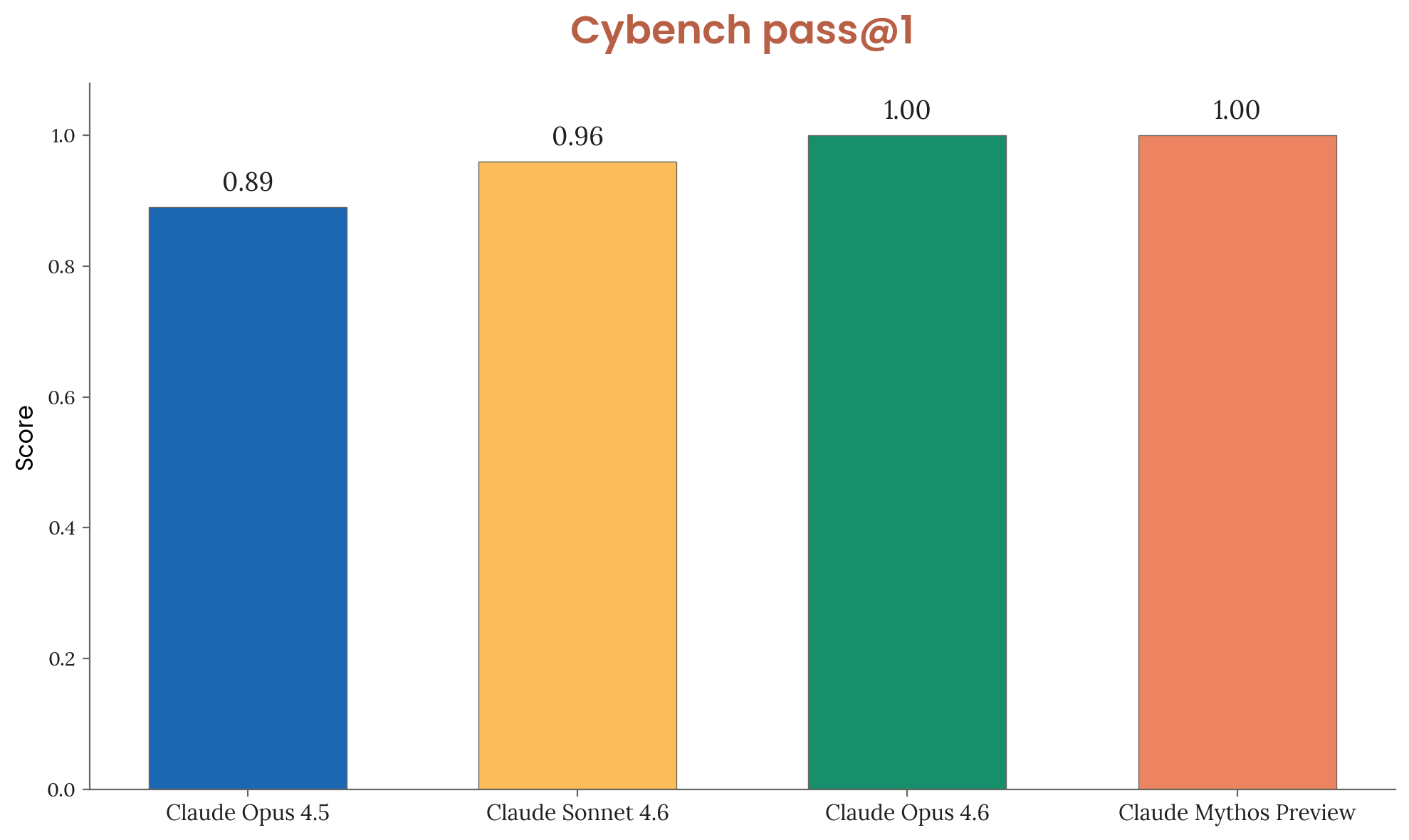
Figure 3.3.1.A — Cybench results, p. 48. Both Opus 4.6 and Mythos Preview achieve perfect 1.00 pass@1, with Mythos needing only 10 trials vs. 30 — benchmark considered saturated.
Status
Anthropic considers Cybench saturated — Claude Mythos Preview achieves 100% pass@1, meaning the benchmark is no longer sufficiently informative of frontier model capabilities.