CyberGym
A benchmark that tests AI agents on their ability to find previously-discovered vulnerabilities in real open-source software projects, referred to as targeted vulnerability reproduction.
Overview
- Tests against 1,507 tasks drawn from real open-source projects
- Given a high-level description of a weakness, the model must reproduce the vulnerability
- Scored as pass@1 (aggregate over the full suite, one attempt per task)
- Paper: Wang, Z., et al. (2025). CyberGym: Evaluating AI agents’ cybersecurity capabilities with real-world vulnerabilities at scale. arXiv:2506.02548
Results on Claude Models
| Model | Score |
|---|---|
| Claude Opus 4.5 | 0.51 |
| Claude Sonnet 4.6 | 0.65 |
| Claude Opus 4.6 | 0.67 |
| Claude Mythos Preview | 0.83 |
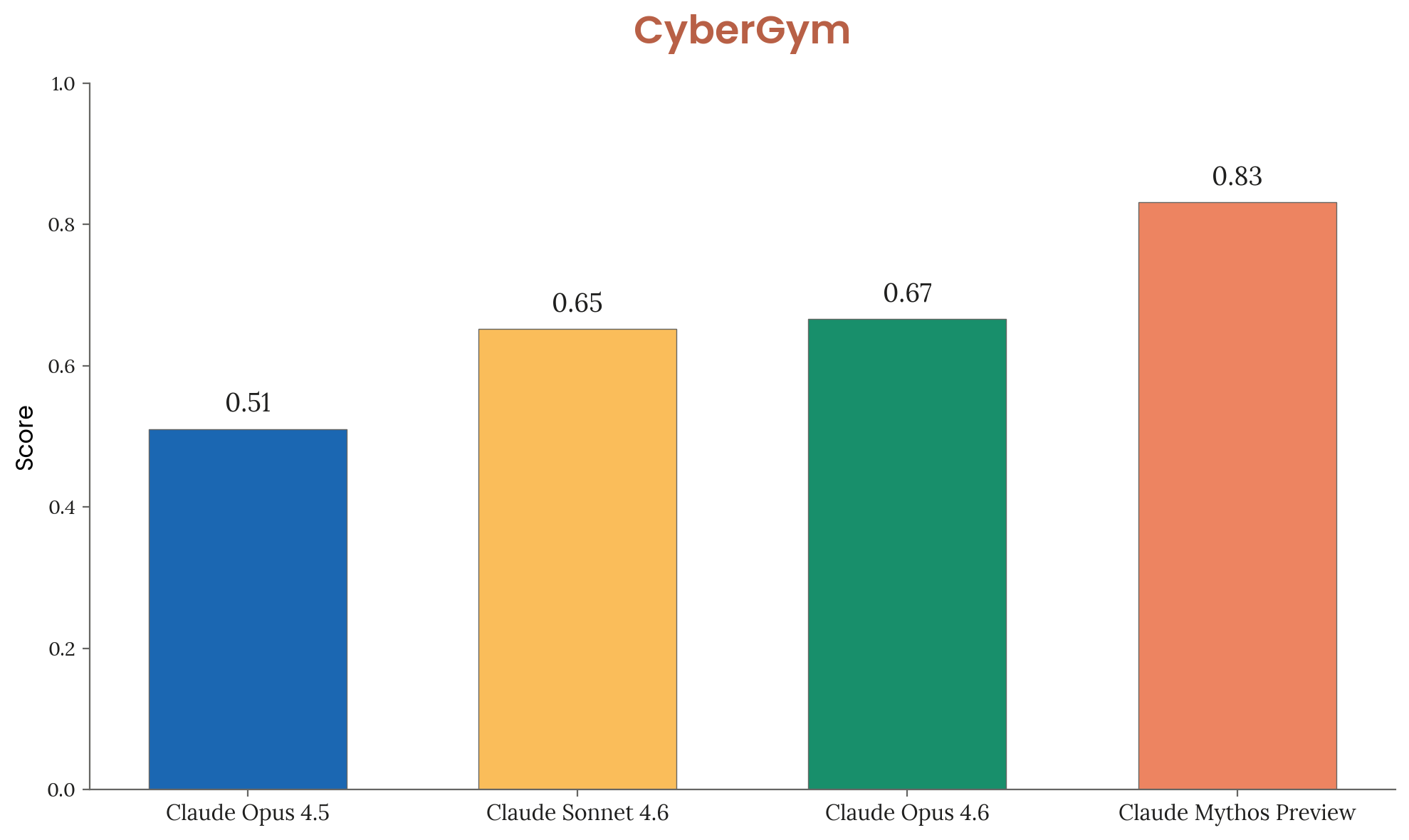
Figure 3.3.2.A — CyberGym results, p. 49. Mythos Preview scores 0.83 on targeted vulnerability reproduction, a 16-point jump over Opus 4.6 (0.67).
Significance
Anthropic considers CyberGym, along with real-world code evaluations, to be more reflective of actual model cybersecurity capability than CTF-style benchmarks like Cybench.