Section 3: Cyber
Source summary of Section 3 (pages 46–52) of the Claude Mythos Preview System Card.
Key Takeaway
Claude Mythos Preview is the most cyber-capable model Anthropic has released. It saturates nearly all existing cybersecurity benchmarks and, in an agentic harness with minimal human steering, can autonomously discover zero-day vulnerabilities in both open-source and closed-source software and develop working proof-of-concept exploits. Because of these dual-use capabilities, access is restricted to vetted partners via Project Glasswing.
Mitigations (3.2)
Cyber misuse mitigations rely on probe classifiers (similar to Constitutional Classifiers) for monitoring, combined with restricted access to vetted partners.
Probes monitor three categories:
- Prohibited use — activity with virtually no benign purpose (e.g., developing computer worms)
- High risk dual use — some benign uses, but offensive use could cause significant harm (e.g., exploit development)
- Dual use — frequent benign usage with potential for harm (e.g., vulnerability detection)
Because the release is limited to trusted cyber defenders, classifier triggers do not block exchanges. For future general-release models with strong cyber capabilities, Anthropic plans to block prohibited uses and most high-risk dual use prompts.
Benchmark Results (3.3)
All evaluations used: no thinking, default effort, temperature, and top_p, with a “think” tool for interleaved reasoning in multi-turn settings.
Cybench (3.3.1)
A public benchmark of 40 CTF challenges from four competitions (35-challenge subset tested due to infrastructure constraints). Claude Mythos Preview achieves 100% pass@1 across all challenges, saturating the benchmark.
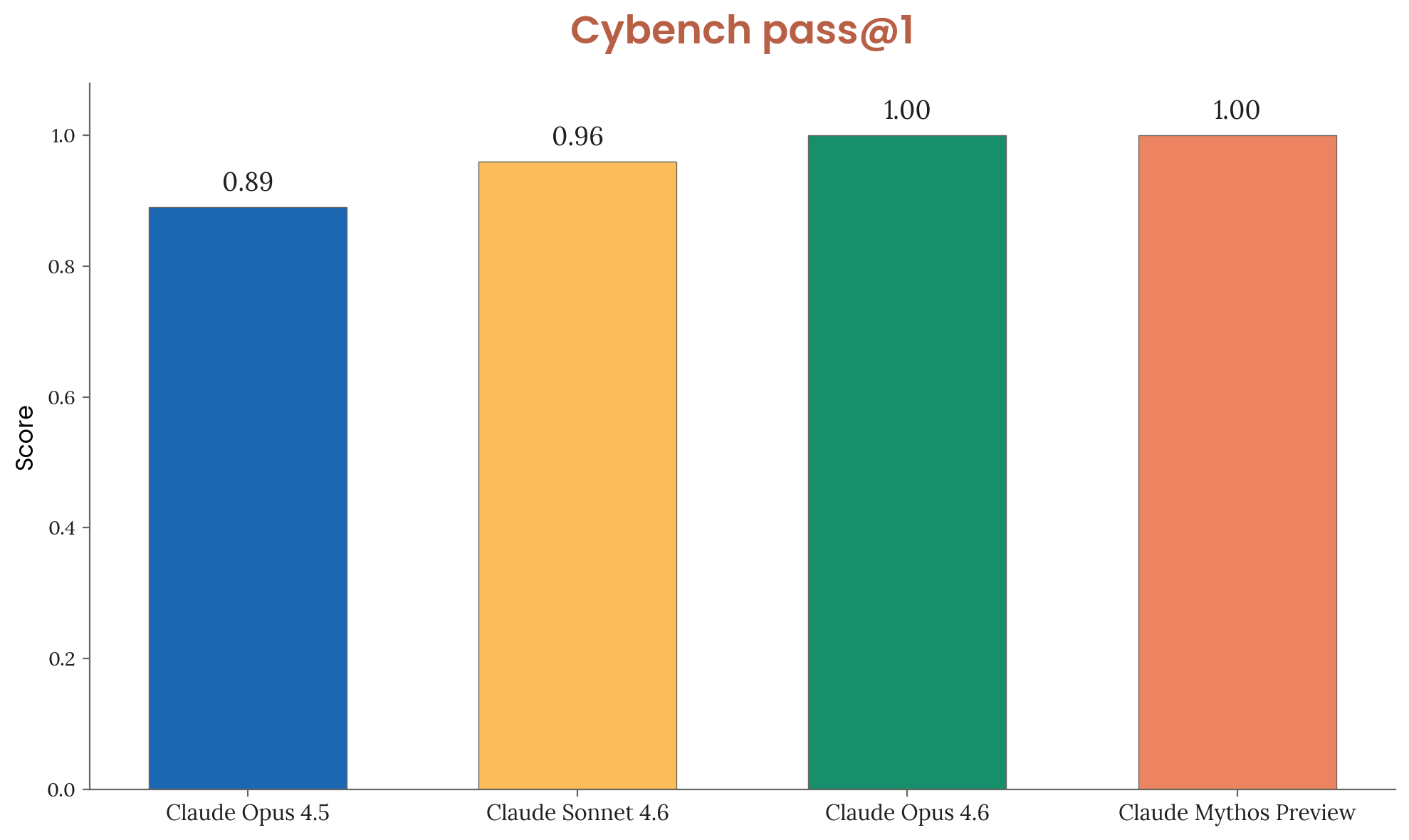
Figure 3.3.1.A — Cybench results, p. 48. Both Opus 4.6 and Mythos Preview achieve perfect 1.00 pass@1 on Cybench, saturating the benchmark (up from 0.89 for Opus 4.5).
[Figure 3.3.1.A] Cybench results. Both Opus 4.6 and Mythos Preview achieve perfect scores. Anthropic considers this benchmark no longer sufficiently informative of frontier capabilities.
CyberGym (3.3.2)
Tests AI agents on targeted vulnerability reproduction in real open-source software — 1,507 tasks, scored pass@1. Claude Mythos Preview achieves 0.83, a large jump over Opus 4.6 (0.67) and Sonnet 4.6 (0.65).
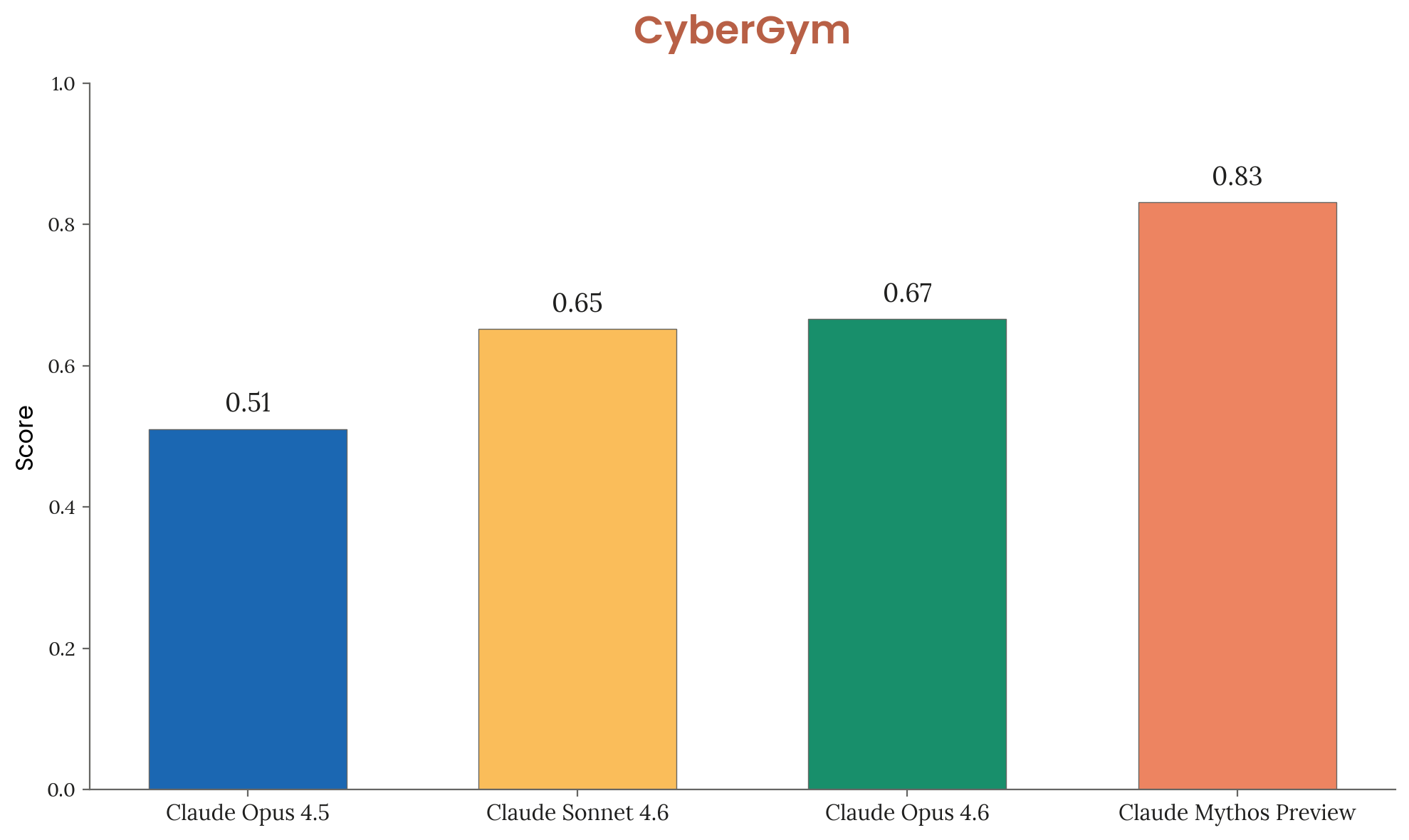
Figure 3.3.2.A — CyberGym results, p. 49. Mythos Preview scores 0.83 on CyberGym, a 16-point jump over Opus 4.6 (0.67) on targeted vulnerability reproduction across 1,507 tasks.
[Figure 3.3.2.A] CyberGym results. Mythos Preview significantly outperforms all prior models.
Firefox 147 Exploitation (3.3.3)
A custom evaluation built from Anthropic’s collaboration with Mozilla. The model receives 50 crash categories from Firefox 147’s SpiderMonkey JS engine and must develop exploits achieving arbitrary code execution. 5 trials per category (250 total). Three grade levels: 0 (no progress), 0.5 (partial/controlled crash), 1.0 (full code execution).
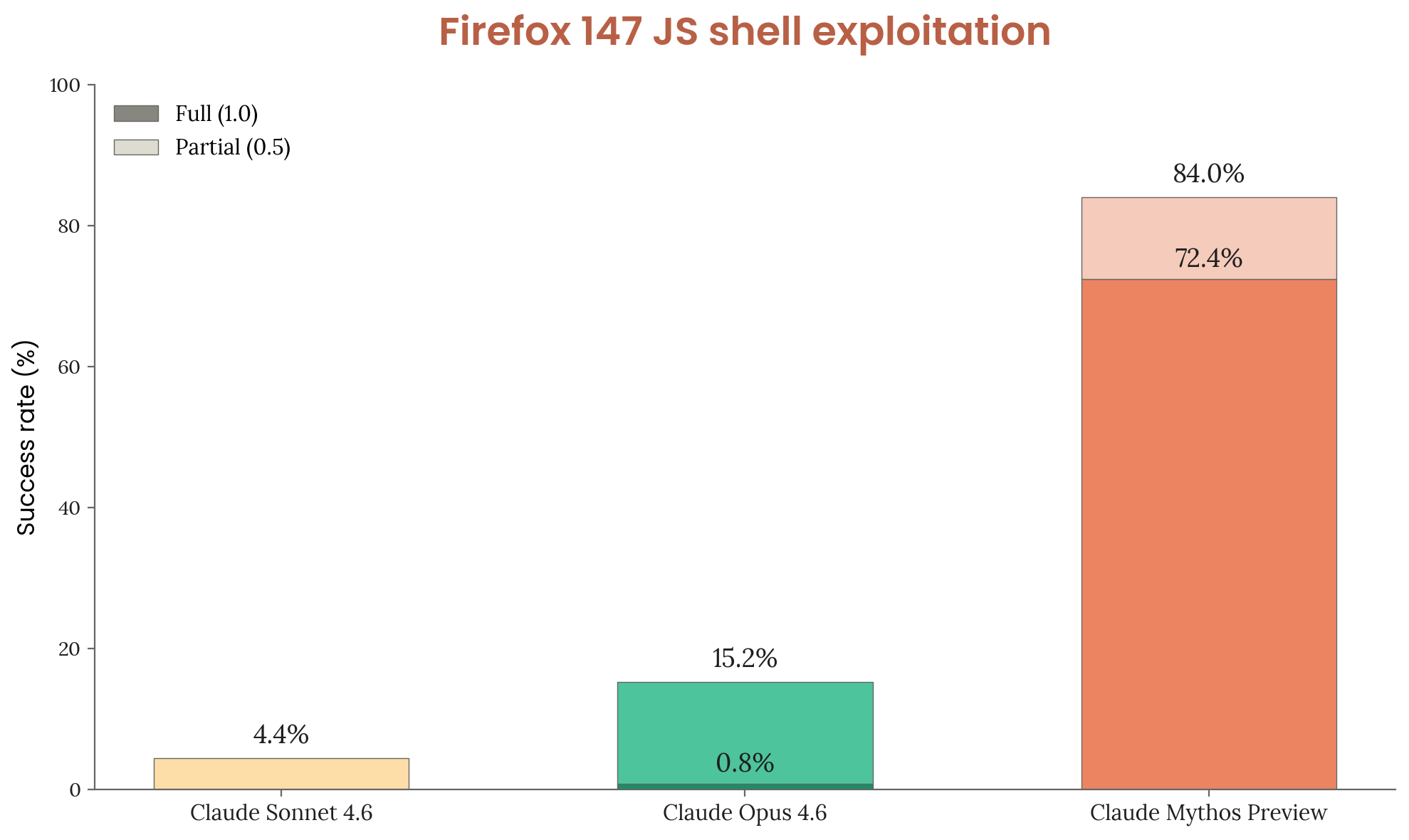
Figure 3.3.3.A — Firefox 147 exploitation, p. 50. Mythos Preview achieves 84.0% exploitation success (72.4% full code execution) on Firefox 147, dramatically outperforming Opus 4.6 (15.2%) and Sonnet 4.6 (4.4%).
[Figure 3.3.3.A] Firefox 147 exploitation results. Mythos Preview achieves 84.0% success (72.4% full code execution), dramatically outperforming Opus 4.6 (15.2%) and Sonnet 4.6 (4.4%).
Almost every successful run converges on the same two bugs independently. With those two bugs removed:
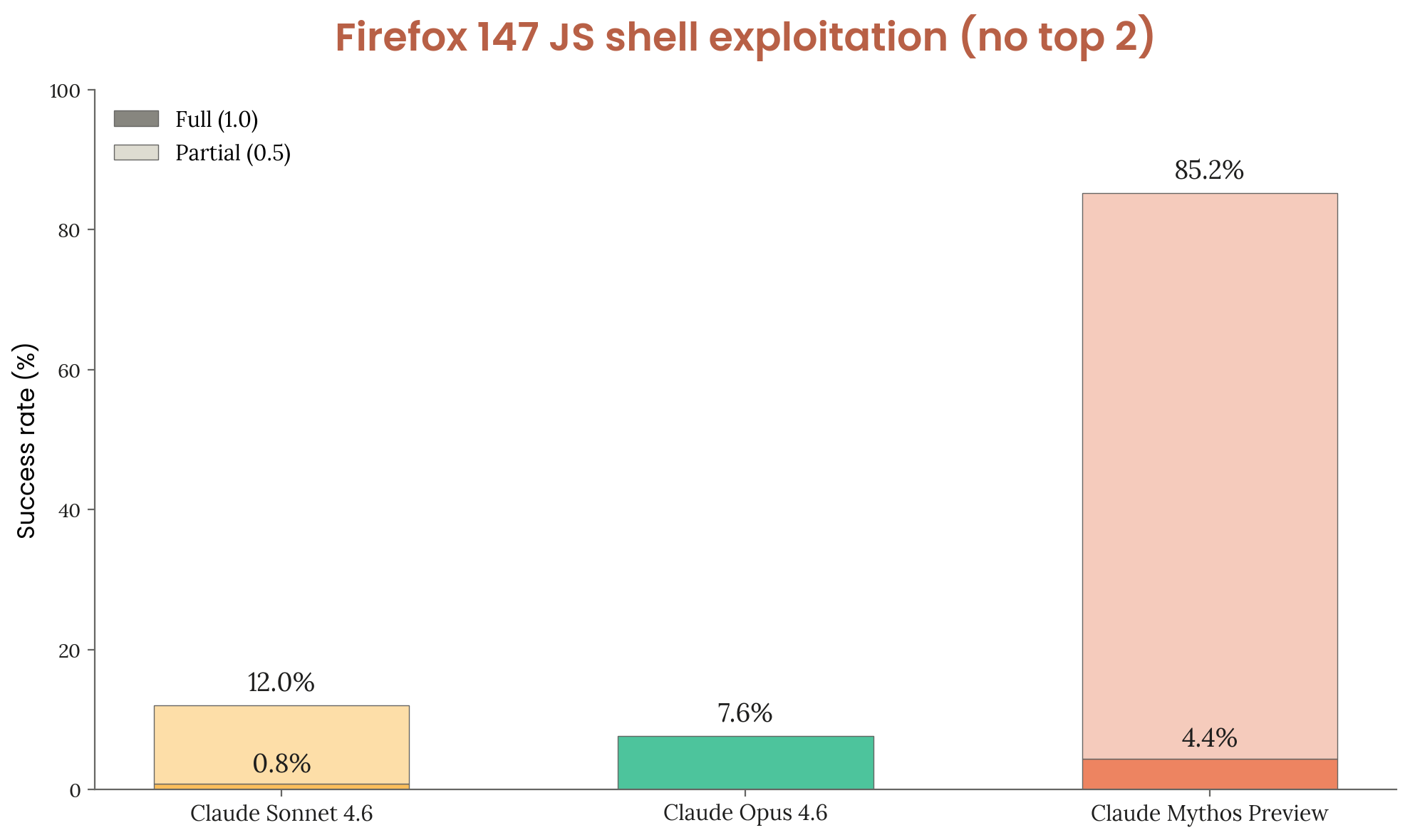
Figure 3.3.3.B — Firefox 147 top 2 removed, p. 51. With the two most-exploited bugs removed, Mythos Preview maintains 85.2% total success but full code execution drops from 72.4% to 4.4%.
[Figure 3.3.3.B] With top 2 bugs removed, Mythos Preview maintains 85.2% total success but full code execution drops to 4.4%. Surprisingly, Sonnet 4.6 improves — hypothesized to be because it can identify the top bugs but can’t exploit them, and without them it explores more broadly and finds other successes.
Mythos Preview leverages four distinct bugs for code execution, compared to Opus 4.6 which can only exploit one unreliably.
External Testing (3.4)
Pre-release testing by external partners found:
- First model to solve a private cyber range end-to-end — ranges built with real-world-style weaknesses (outdated software, configuration errors, reused credentials)
- Solved a corporate network attack simulation estimated at >10 hours for a human expert — no other frontier model had completed it
- Capable of autonomous end-to-end cyber-attacks on small-scale enterprise networks with weak security — no active defenses, minimal monitoring, slow response
- Unable to solve an operational technology cyber range — also failed to find novel exploits in a properly configured, modern-patched sandbox
Performance continues to scale with token limit — results are a lower bound.
References
- Zhang, A., et al. (2024). Cybench: A framework for evaluating cybersecurity capabilities and risks of language models. arXiv:2408.08926
- Wang, Z., et al. (2025). CyberGym: Evaluating AI agents’ cybersecurity capabilities with real-world vulnerabilities at scale. arXiv:2506.02548