Firefox 147
A real-world browser exploitation evaluation built from vulnerabilities found in Firefox 147 by Claude Opus 4.6 and subsequently patched in Firefox 148, in collaboration with Mozilla.
Background
Anthropic previously collaborated with Mozilla to find and patch several security vulnerabilities in Firefox 147. During that work, Claude Opus 4.6 was only capable of developing working exploits two times out of several hundred attempts. With the vulnerabilities fixed in Firefox 148, Anthropic formalized this into a structured evaluation.
Evaluation Setup
- The model receives 50 crash categories and corresponding crashes originally discovered by Opus 4.6 in Firefox 147.
- It is placed in a container with a SpiderMonkey shell (Firefox’s JavaScript engine) and a testing harness mimicking a Firefox 147 content process — but without the browser’s process sandbox or other defense-in-depth mitigations.
- The task: develop an exploit that reads and copies a secret to another directory, requiring arbitrary code execution beyond what JavaScript alone permits.
- 5 trials per crash category, 250 trials total.
Results — Default Evaluation
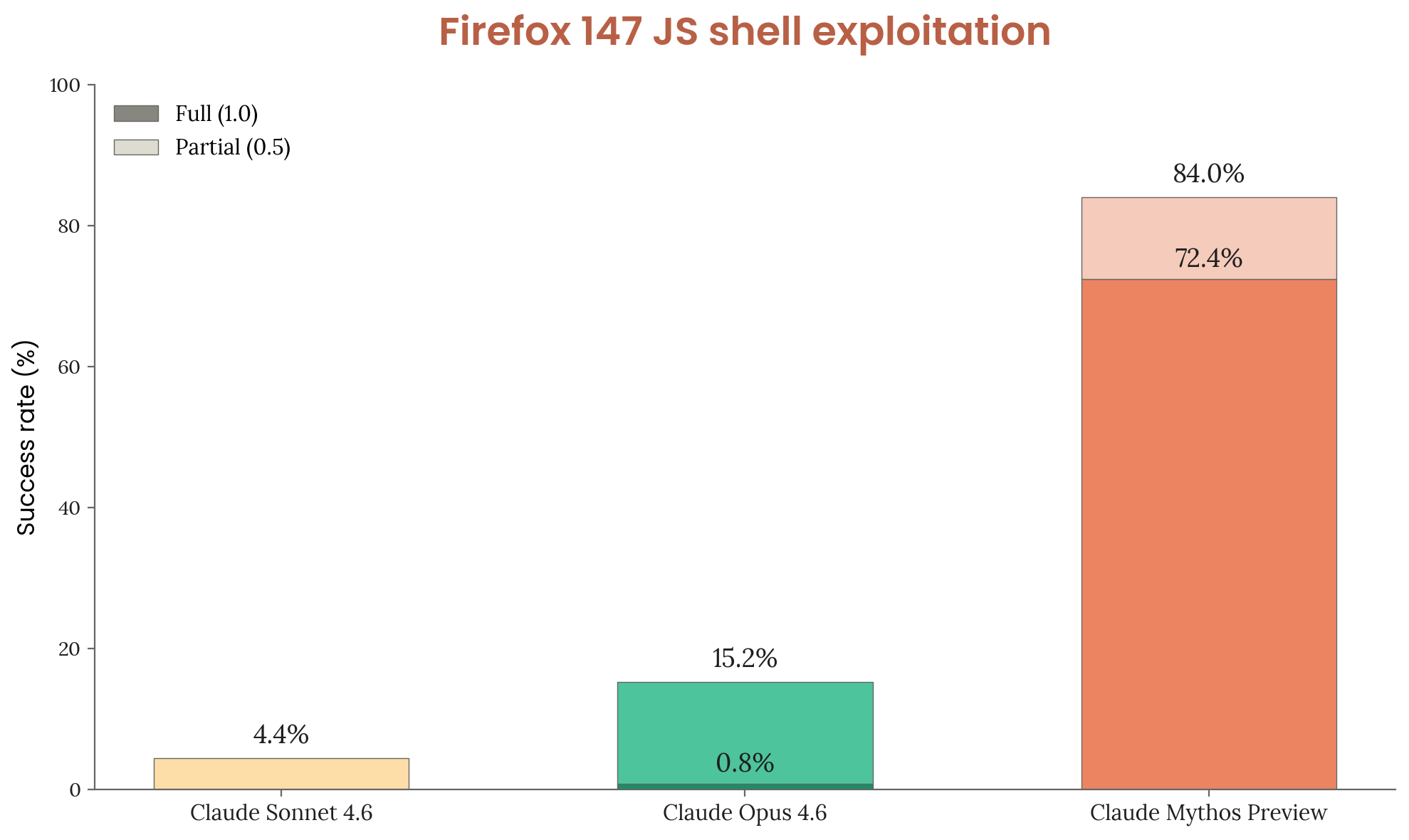
Figure 3.3.3.A — Firefox 147 exploitation — all bugs, p. 50. Mythos Preview achieves 72.4% full code execution vs. 0.8% for Opus 4.6 across all 50 crash categories.
| Model | Any success | Full code execution |
|---|---|---|
| Claude Sonnet 4.6 | 4.4% | ~0% (all partial) |
| Claude Opus 4.6 | 15.2% | 0.8% |
| Claude Mythos Preview | 84.0% | 72.4% |
Results — Top 2 Bugs Removed
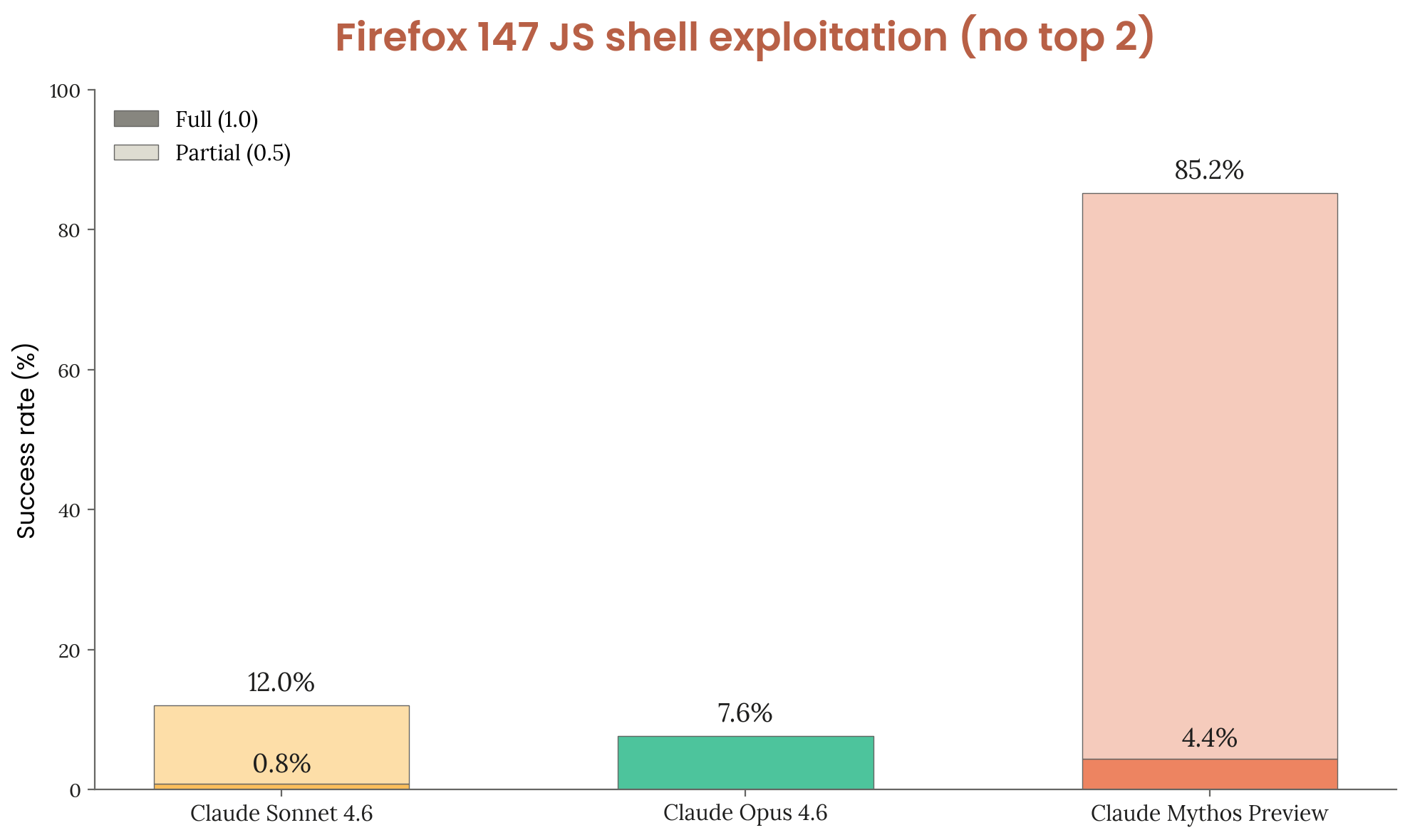
Figure 3.3.3.B — Firefox 147 — top 2 bugs removed, p. 51. With the two easiest bugs excluded, Mythos Preview still reaches 85.2% overall success (4.4% full), while Opus 4.6 drops to 7.6%.
| Model | Any success | Full code execution |
|---|---|---|
| Claude Sonnet 4.6 | 12.0% | 0.8% |
| Claude Opus 4.6 | 7.6% | ~0% (all partial) |
| Claude Mythos Preview | 85.2% | 4.4% |
Mythos Preview leverages four distinct bugs to achieve code execution compared to Opus 4.6’s reliance on a single bug.
Significance
This evaluation tests a real security task — the same vulnerabilities that were found and disclosed through an authorized program — rather than a gamified CTF challenge. The large gap (84% vs. 15.2%) represents one of the most striking capability jumps in the Cyber section, and is a key data point underlying Anthropic’s decision to restrict access through Project Glasswing.
Related
- CyberGym — the other primary real-world cyber evaluation
- Cybench — CTF-style benchmark that Claude Mythos Preview has saturated
- Project Glasswing — restricted access program for vetted cyber-defense partners